
The research community often praises reconfigurable intelligent surfaces (RISs) as a transformative technology. By controlling parts of wireless propagation channels, we can improve the bit rates by increasing the received signal strength, mitigating interference, enhancing channel ranks, etc. The potential benefits RISs can bring to wireless networks are now well documented, and several of them have also been demonstrated experimentally. However, the RIS technology also introduces several practical complications that one must be mindful of. In this blog post, I will give two examples of the dark side of the RIS technology.
Pilot contamination between operators
Suppose a telecom operator deploys an RIS to enhance the performance experienced by its customers. The academic literature is full of algorithms that can be used to that end. Each time the operator changes the RIS configuration, it will affect not only the wireless channels within its licensed frequency band but also the channels in many neighboring bands. The phase-shifting in each RIS element acts as an approximately linear-phase filtering operation, which shifts the phases of reflected signals (proportionally to their carrier frequencies) both in the intended and adjacent bands. Since there is no non-linear distortion, the operator’s wireless signals are maintained in their designated band. Nevertheless, the operator messes with the channel characteristics in neighboring bands every time it reconfigures its RIS. In the best-case scenario, the systems operating in neighboring bands only experience additional fading variations. In the worst-case scenario, they will suffer from substantial performance degradation.
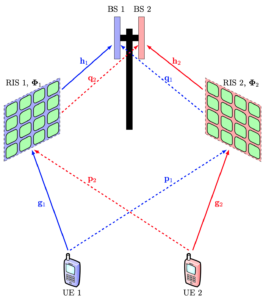
An instance of the latter scenario appears when two telecom operators deploy RISs in the same coverage area. We studied this scenario in a recent paper. 5G networks typically use time-division duplex (TDD) bands, and the operators are time-synchronized, so they switch between uplink and downlink simultaneously. This implies that the considered operators will send pilot sequences in parallel, which is usually fine because they are transmitted in different bands. However, if each operator uses its pilot sequences for RIS reconfiguration that helps its own users, it will also modify the other operator’s channels in undesired ways after the estimation has occurred. This leads to a new kind of pilot contamination effect, which differs from that in Massive MIMO but leads to the same bottlenecks: reduced estimation quality and a performance limit at high signal-to-noise ratios (SNRs). Consequently, if a large-scale deployment of RIS occurs in cellular networks, we will see not only the intended performance improvements but also occasional unexpected degradations. More research is needed to quantify this effect and what can be done to mitigate it.
Malicious RIS
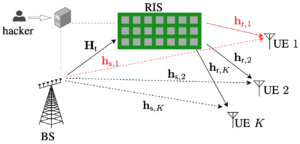
While the pilot contamination caused between telecom operators is an unintentional disturbance, RIS could also be used for intentional “silent” jamming. In a recent paper, we analyze the situation where a hacker takes control of an operator’s RIS and turns it into a malicious RIS. Instead of maximizing the received signal strength at a specific user device, the RIS can be configured to minimize the signal strength. Since this is achieved by causing destructive interference over the air, the user device will perceive this as having poor coverage. Conventional jamming builds on sending a strongly interfering signal to prevent data decoding, and this can be easily detected. By contrast, the silent jamming caused by a malicious RIS is hard to detect since it destroys the channel without introducing new signals. In our paper, we demonstrate how a malicious RIS can avoid detection by only destroying the channel for one user device while other devices are unaffected. We also show that malicious reflection is possible even if the RIS has imperfect channel knowledge.
In summary, there is a dark side to the RIS technology. It can both manifest itself through unintentional tampering with the channels in neighboring frequency bands and through the risk that an RIS is hacked and turned into a malicious RIS that degrades rather than improves communication performance. Careful regulation, standardization, hardware design, and security will be required to overcome these challenges.


