In what ways could we improve cellular-massive-MIMO based 5G? Well, to start with, this technology is already pretty good. But coverage holes, and difficulties to send multiple streams to multi-antenna users because of insufficient channel rank, remain issues.
Perhaps the ultimate solution is distributed MIMO (also known as cell-free massive MIMO). But while this is at heart a powerful technology, installing backhaul seems dreadfully expensive, and achieving accurate phase-alignment for coherent multiuser beamforming on downlink is a difficult technical problem. Another option is RIS – but they have large form factors and require a lot of training and control overhead, and probably, in practice, some form of active filtering to make them sufficiently band-selective.
A different, radically new approach is to deploy large numbers of physically small and cheap wireless repeaters, that receive and instantaneously retransmit signals – appearing as if they were ordinary scatterers in the channel, but with amplification. Repeaters, as such, are deployed today already but only in niche use cases. Could they be deployed at scale, in swarms, within the cells? What would be required of the repeaters, and how well could a repeater-assisted cellular massive MIMO system work, compared to distributed MIMO? What are the fundamental limits of this technology?
At last, some significant new research directions for the wireless PHY community!
The golden frequencies for wireless access are in the band below 6 GHz. Why are these frequencies so valuable? The reasons, of course, are rooted in the physics. First, the wavelength is short enough that a (numerically) large array has an attractive form factor, enabling spatial multiplexing even from a single antenna panel. At the same time, the wavelength is large enough that a sufficiently large aperture can be obtained with a reasonable number of antennas – which, in turn, directly translates into a favorable link budget and high coverage. Second, below 6 GHz, Doppler is low enough, even at high mobility, that reciprocity-based beamforming based on uplink pilots for channel estimation works without relying on prior assumptions on the propagation environment, let alone on the fading statistics. This directly translates into robustness, simplicity of implementation, and scalability with respect to the number of service antennas. Third, these frequencies are not hindered so much by blockage, and strong multipath components can guarantee connectivity even when there is no line-of-sight, while in contrast, for mmWave a human blocking the line-of-sight path can suffice to break the link. Finally, analog microelectronics for the golden bands is mature, and very energy-efficient.
Distributed MIMO (D-MIMO) with reciprocity-based beamforming is the natural way of best exploiting the golden frequencies. This technology naturally operates in the [geometric] near-field of the “super-array” collectively constituted by all antenna panels together. In fact, the actual antenna deployment hardly matters at all! With reciprocity-based beamforming, the physical shape of the actual beams, and grating lobe phenomena in particular, become irrelevant. If anything, given a set of antennas, it is advantageous to spread them out over as large aperture as possible. The only definite no-no is to place antennas closer than half a wavelength together: such dense packing of antennas is almost never meaningful, as sampling points lambda/2-spaced apart captures essentially all the degrees of freedom of the field; putting the antennas closer results in coupling effects that are usually of more harm than benefit.
REINDEER is the European project that develops and demonstrates D-MIMO for the golden frequencies. What are the most important technical challenges? One is, down-to-earth, to handle the vast amounts of baseband data, and process them in real time. Another is time and phase synchronization of distributed MIMO arrays: antenna panels driven by independent local oscillators must be re-calibrated for joint reciprocity every time the oscillators have drifted apart. Locking the clocks using cabling is possible in principle, but considered very expensive to deploy. A third is initial access, covering space uniformly with system information signals, and waking up sleeping devices. A fourth is energy-efficiency, at all levels in the network. A fifth is the integration of service of energy-neutral devices that communicate via backscattering. D-MIMO naturally offers the infrastructure for that, permitting simultaneous transmission and reception from different panels in a bistatic setup; however, these activities break the TDD flow and must be carefully integrated into the workings of the system.
If sub-6 GHz are gold, then what is silver? Perhaps right above: the 7-15 GHz band, that is intended in 6G to extend the “main capacity” layer. It appears that these bands can still be suitable mobile applications, and that higher carriers (28 GHz, 38 GHz) are appropriate for fixed wireless access mostly. But the sub-6 GHz bands will remain golden and the first choice for the most challenging situations: high mobility, area coverage, and outdoor-to-indoor.
The 2021 IEEE GLOBECOM workshop on “Wireless Communications for Distributed Intelligence” will be held in Madrid, Spain, in December 2021. This workshop aims at investigating and re-defining the roles of wireless communications for decentralized Artificial Intelligence (AI) systems, including distributed sensing, information processing, automatic control, learning and inference.
We invite submissions of original works on the related topics, which include but are not limited to the following:
Network architecture and protocol design for AI-enabled 6G
Federated learning (FL) in wireless networks
Multi-agent reinforcement learning in wireless networks
Communication efficiency in distributed machine learning (ML)
Energy efficiency in distributed ML
Cross-layer (PHY, MAC, network layer) design for distributed ML
Wireless resource allocation for distributed ML
Signal processing for distributed ML
Over-the-air (OTA) computation for FL
Emerging PHY technologies for OTA FL
Privacy and security issues of distributed ML
Adversary-resilient distributed sensing, learning, and inference
Fault tolerance in distributed stochastic gradient descent (DSGD) systems
Fault tolerance in multi-agent systems
Fundamental limits of distributed ML with imperfect communication
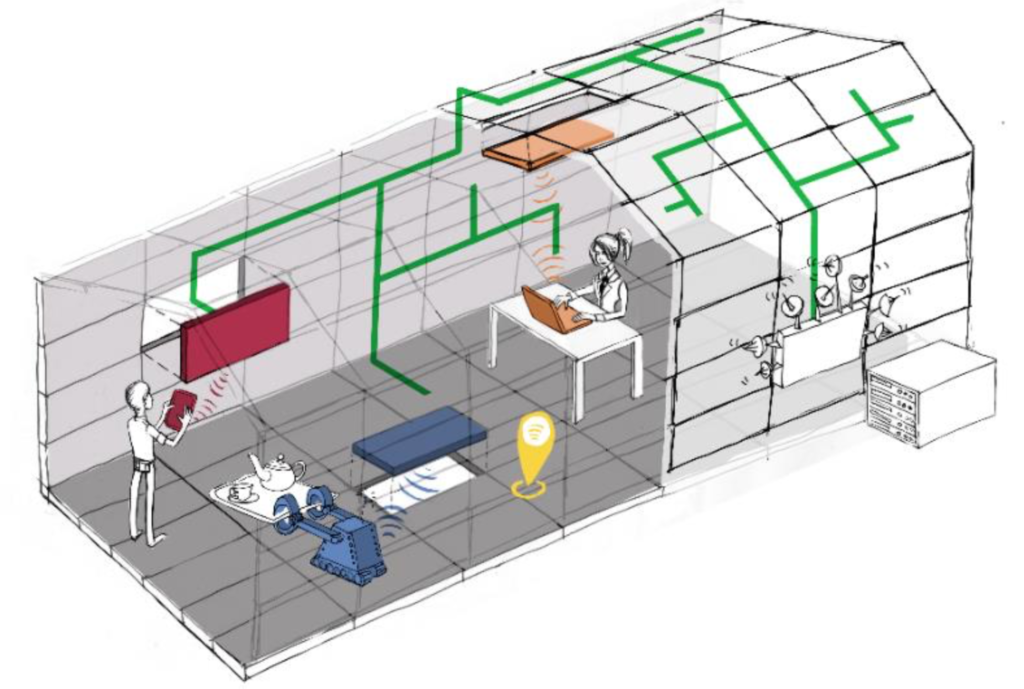
A new EU-funded 6G initiative, the REINDEER project, joins forces from academia and industry to develop and build a new type of multi-antenna-based smart connectivity platform integral to future 6G systems. From Ericsson’s new site:
The project’s name is derived from REsilient INteractive applications through hyper Diversity in Energy-Efficient RadioWeaves technology, and the development of “RadioWeaves” technology will be a key deliverable of the project. This new wireless access infrastructure consists of a fabric of distributed radio, compute and storage. It will advance the ideas of large-scale intelligent surfaces and cell-free wireless access to offer capabilities far beyond future 5G networks. This is expected to offer capacity scalable to quasi-infinite, and perceived zero latency and interaction with a large number of embedded devices.
I taught a course on complex networks this fall, and one component of the course is a hands-on session where students use the SNAP C++ and Python libraries for graph analysis, and Gephi for visualization. One available dataset is DBLP, a large publication database in computer science, that actually includes a lot of electrical engineering as well.
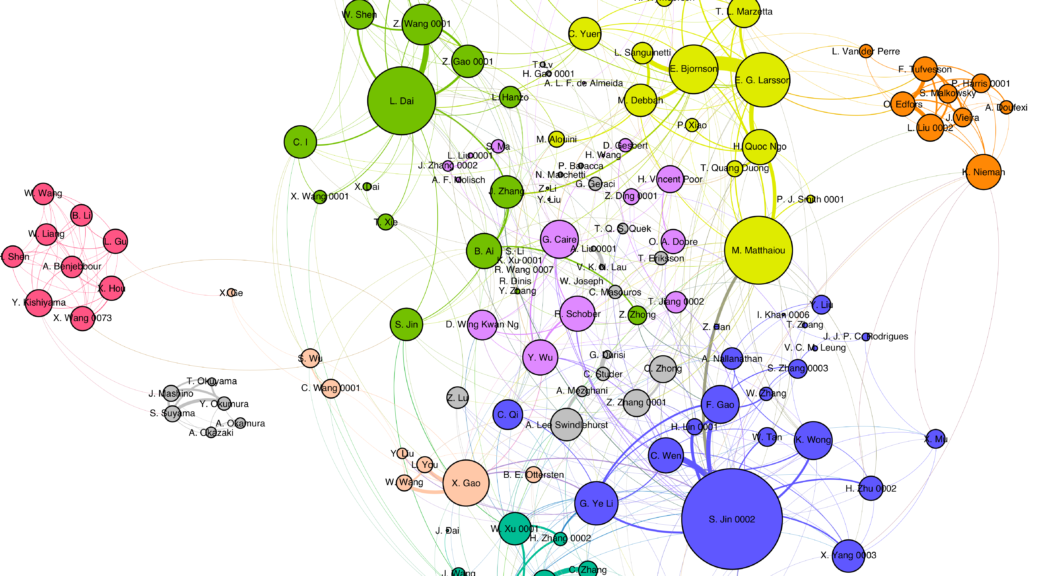
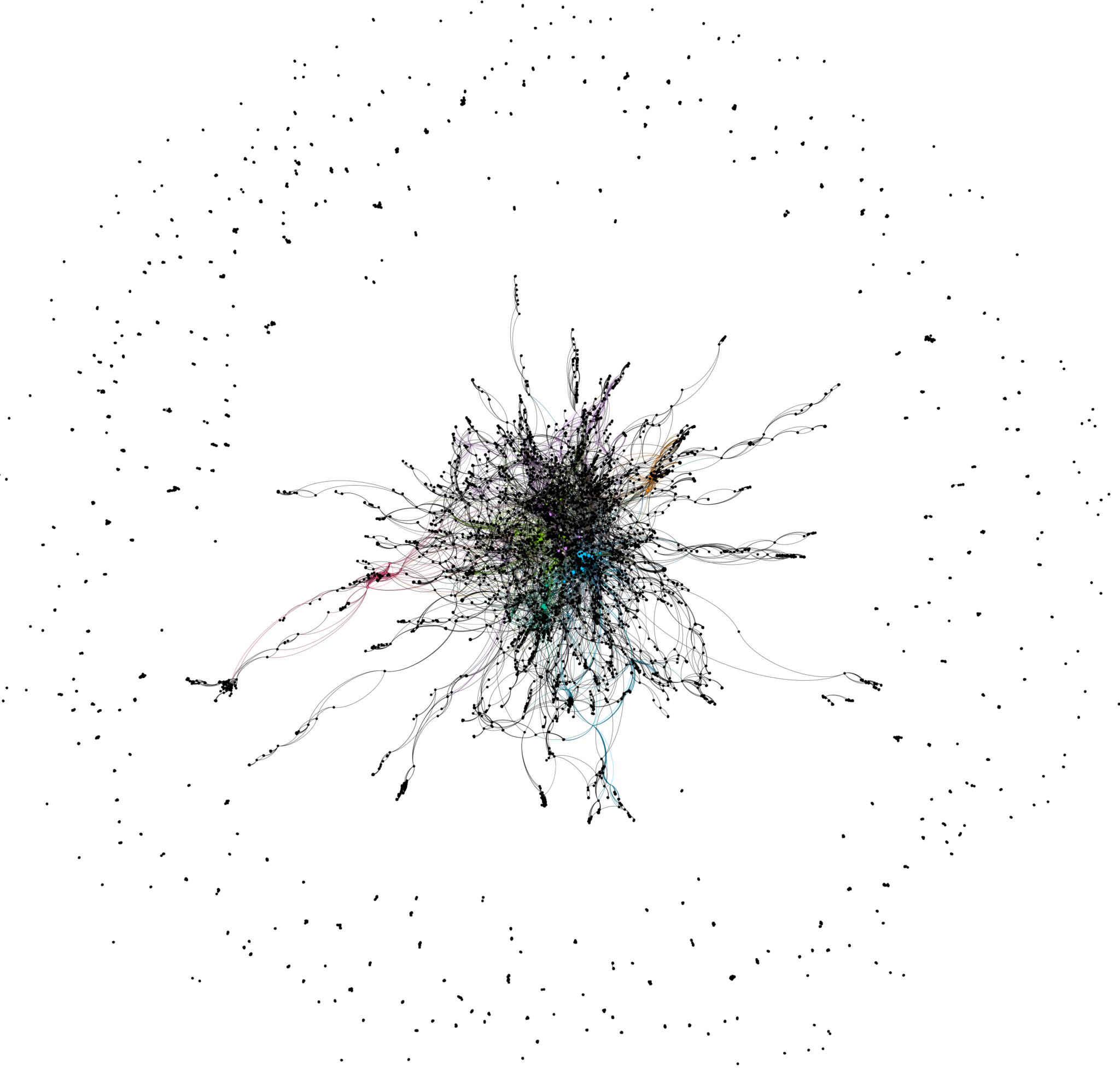
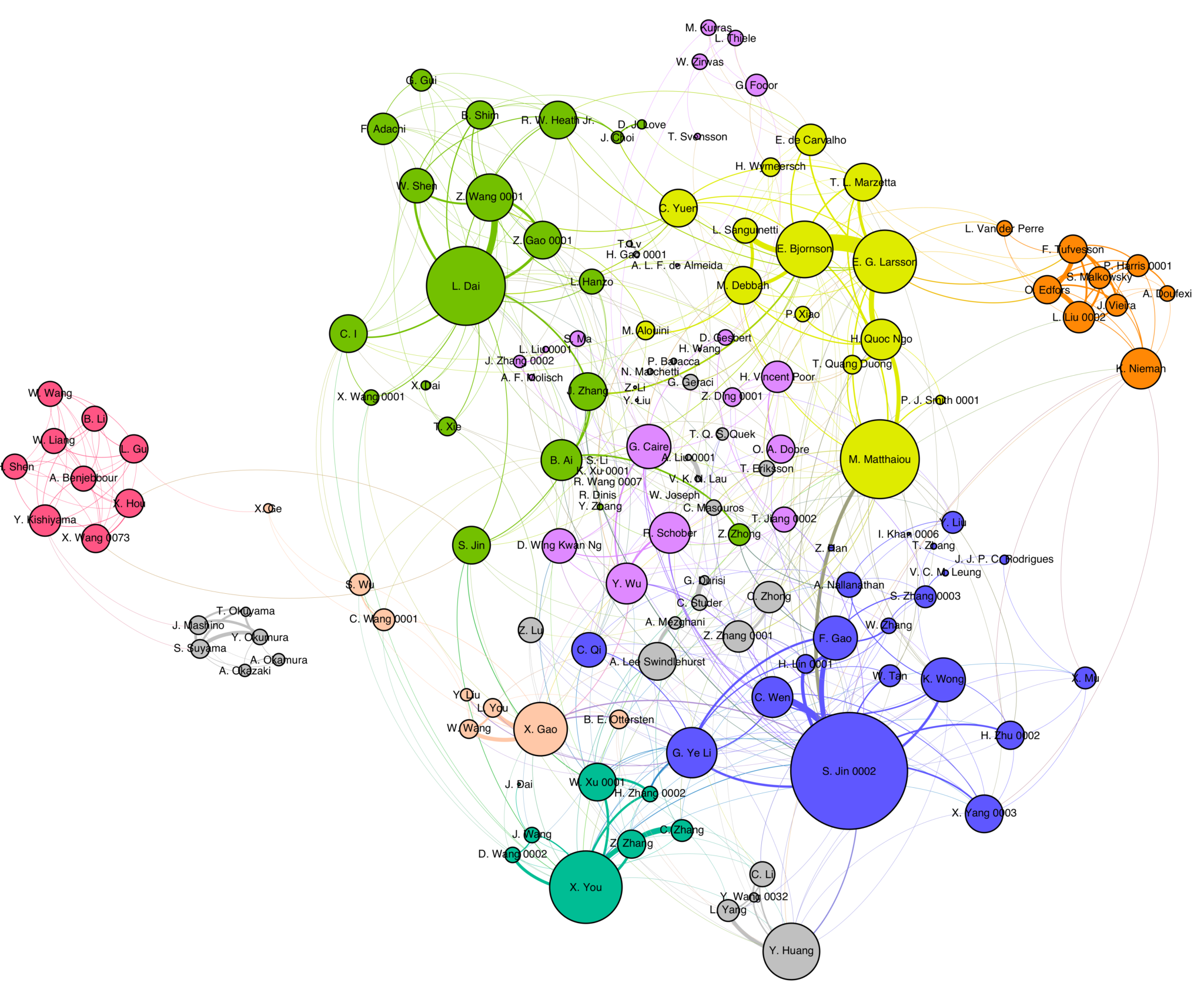
In a small experiment I filtered DBLP for papers with both “massive” and “MIMO” in the title, and analyzed the resulting co-author graph. There are 17200 papers and some 6000 authors. There is a large connected component, with over 400 additional much smaller connected components!
Then I looked more closely at authors who have written at least 20 papers. Each node is an author, its size is proportional to his/her number of “massive MIMO papers”, and its color represents identified communities. Edge thicknesses represent the number of co-authored papers. Some long-standing collaborators, former students, and other friends stand out. (Click on the figure to enlarge it.)
To remind readers of the obvious, prolificacy is not the same as impact, even though they are often correlated. Also, the study is not entirely rigorous. For one thing, it trusts that DBLP properly distinguishes authors with the same name (consider e.g., “Li Li”) and I do not know how well it really does that. Second, in a random inspection all papers I had filtered out dealt with “massive MIMO” as we know it. However, theoretically, the search criterion would also catch papers on, say, MIMO control theory for a massive power plant. Also, the filtering does miss some papers written before the “massive MIMO” term was established, perhaps most importantly Thomas Marzetta’s seminal paper on “unlimited antennas”. Third, the analysis is limited to publications covered by DBLP, which also means, conversely, that there is no specific quality threshold for the publication venues. Anyone interested in learning more, drop me a note.
Cell-free massive MIMO might be one of the core 6G physical layer technologies. One of my students, Giovanni Interdonato, defended his Ph.D. thesis on this topic earlier this week. In this video, he speaks with me about his thesis work and his time as a doctoral student.