
I was asked to review my own papers three times during 2018. Or more precisely, I was asked to review papers by other people that contain the same content as some of my most well-cited papers. The review requests didn’t come from IEEE journals but less reputed journals. However, the papers were still written in such a way that they would likely pass through the automatic plagiarism detection systems that IEEE, EDAS, and others are using. How is that possible? Here is an example of how it could look like.
Original:
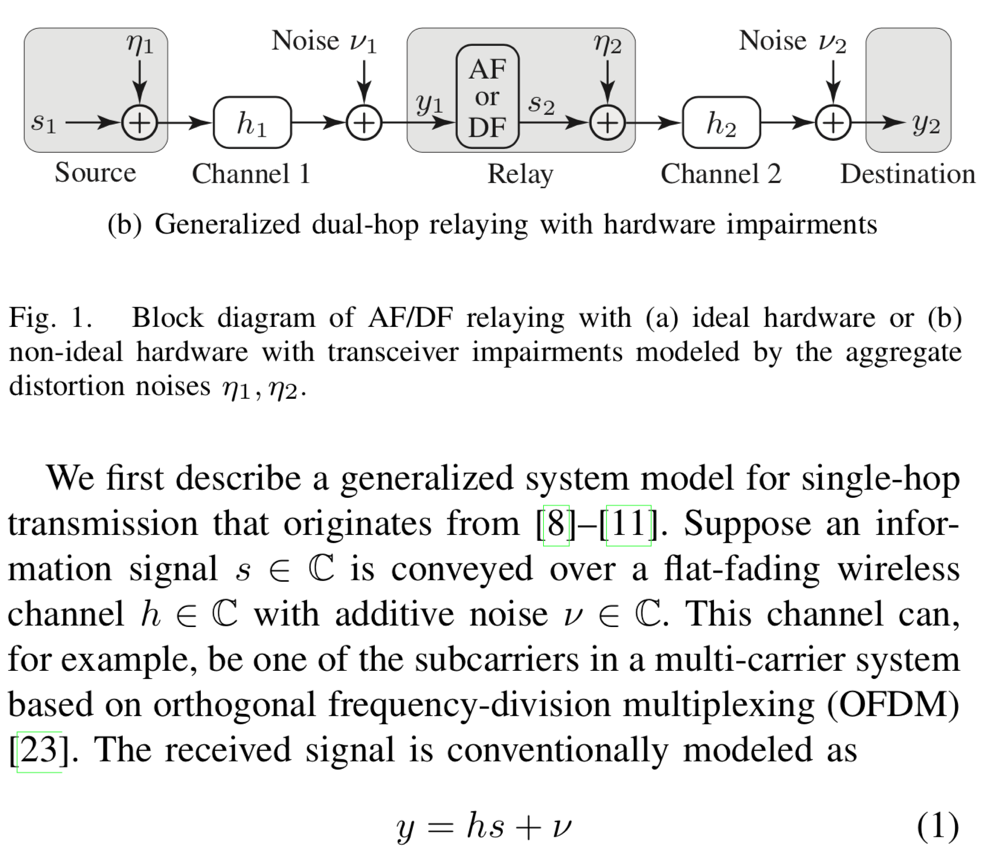
Plagiarized version:
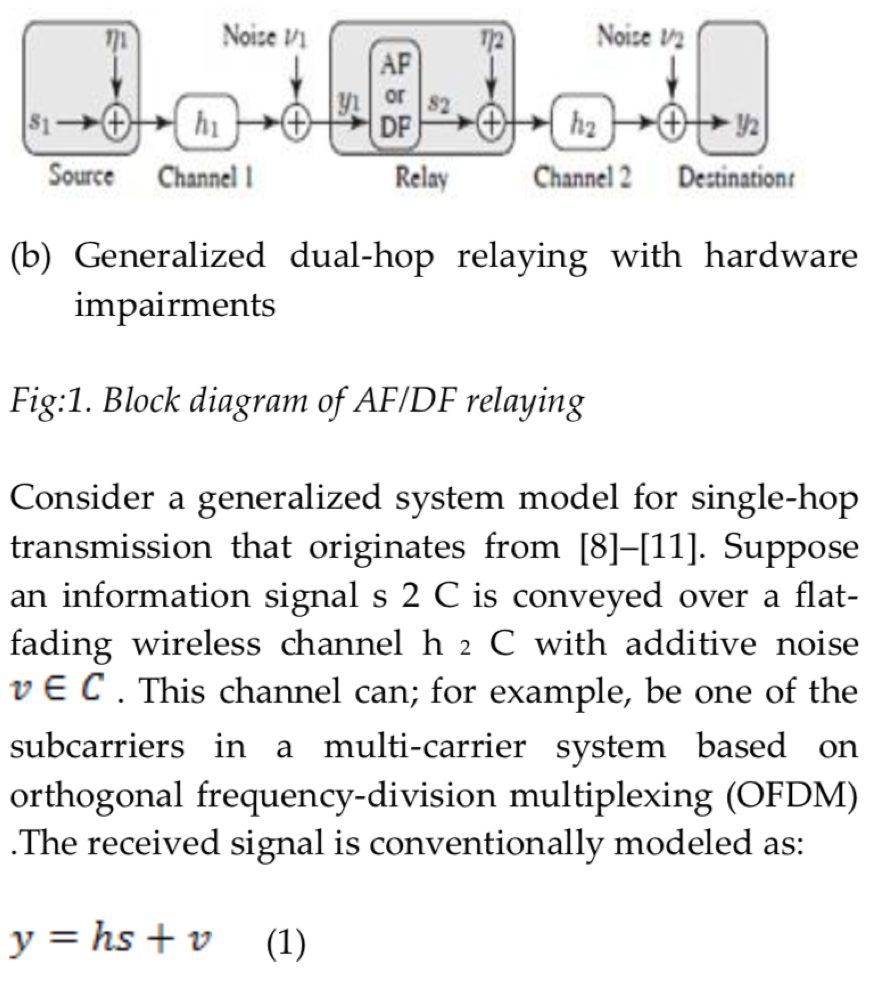
As you can see, the authors are using the same equations and images, but the sentences are slightly paraphrased and the inline math is messed up. The meanings of the sentences are the same, but the different wording might be enough to pass through a plagiarism detection system that compares the words in different documents without being able of understanding the context. (I have better examples of this than the one shown above, but I didn’t want to reveal myself as a reviewer of those papers.)
This approach to plagiarism is known as rogeting and basically means that you replace words in the original text with synonyms from a thesaurus with the purpose of fooling plagiarism detection systems. There are already online tools that can do this, often resulting unnatural sentence structures, but the advances in deep learning and natural language processing will probably help to refine these tools in the near future.
Is this an increasing problem?
This is hard to tell, but there are definitely indications in that direction. The reason might be that digital technology has made it easier to plagiarize. If you want to plagiarize a scientific paper, you don’t need to retype every word by hand. You can simply download the LaTeX code of the paper from ArXiV.org (everything that an author uploads can be downloaded by others) and simply change the author names and then hide your misconduct by rogeting.
On the other hand, plagiarism detection systems are also becoming more sophisticated over time. My point is that we should never trust these systems as being reliable because people will always find ways to fool them. The three plagiarized papers that I detected in 2018 were all submitted to less reputed journals, but they apparently had a functioning peer-review system where researchers like me could spot the similarities despite the rogeting. Unfortunately, there are plenty of predatory journals and conferences that might not have any peer-review whatsoever and will publish anything if you just pay them to do so.
Does anyone benefit from plagiarism?
I am certainly annoyed by the fact that some people have the dishonesty to steal other people’s research and pretend that it is their research. At the same time, I’m wondering if anyone really benefits from doing that? The predatory journals make money from it, but what is in it for the authors? Whenever I review the CV of someone that applies for a position in my group, I have a close look at their list of publications. If it only contains papers published in unknown journals and conferences, I treat it as if the person has no real publications. I might even regard it as more negative to have such publications in the CV than to have no publications at all! I suppose that many other professors do the same thing, and I truly hope that recruiters at companies also have the skills of evaluating publication lists. Having published in a predatory journal must be viewed as a big red flag!
In answer to your question “what is in it for the authors”, remember that the promotion system in many countries depends on the number of journal publications, regardless of the quality of the results. It’s the count that matters. By publishing such papers, the authors get promoted to Associate and then full Professor positions.
Yes, that is true. And I hope that pay-to-publish journals are excluded from those systems, or at least they need to be excluded in the future if the system should make any sense.
That is definitely true. That’s the case in Libya, unfortunately.
This is very unfortunate. Presence of pay to publish journals means that we’ll still have low quality papers in future as well.
Indeed. But I think it is ok to publish low quality papers (everything cannot be of high scientific quality) as long as these papers are not plagiarizing other people’s papers.
I would want to add something to this –
Articles published in IEEE outlets themselves are not immune to plagiarism, especially the type described in this blog (rogeting). I do not want to provide examples in the open for legal reasons but can do so in a private email.
While recruiting for a position, especially in the Sciences and Engineering, it is probably a good idea to test the applicant for a sound knowledge of the fundamentals in the subject area and then look at the publication record.
I completely agree with this unfortunate situation and yes, ML tools may help but one question regarding the rogeted content above: the equation (y = hs +v) is a basic equation, how can someone write it differently? And if you have to explain the basic system, you will use similar terminology and mathematics. I would like to know what can authors do in this case or how should they do it? Thank you in advance
There might not exist a simple way to declare what is plagiarism and what is not. I think the definition should be that someone intentionally presents someone else’s work as his/her own. Just including a basic equation like y = hs + v in the system model is not the problem, but when the “main contribution” of the paper is copied from another paper without reference. This was the problem with the paper that I made screenshots from, although it might not be visible from the screenshots. Since it is hard to prove what is done intentionally, the rule in academia is that one should always point out in a paper what is claimed to be novel and what can be found in prior works (including references to those works).
Another problem, I have seen that many authors intentionally or unintentionally suppress references related to the topic of the presented paper to prove the novelty.