Much wireless communication research in the past five years has been motivated by 6G needing the results. The 6G standardization has recently begun, so in the coming years, we will see which “6G candidate technologies” will be utilized and which will not. Research papers often focus on revolutionary new features, while technology development is often evolutionary since the demand for new features comes gradually.
Although we have yet to determine what technology components will be used, there is much certainty around things like standardization timelines, new feature categories, spectrum candidates, performance metrics, and the interplay between different stakeholders. I explain this in a new 18-minute video about 6G, where I answer what 6G truly is, why it is needed, and how it is developed.
For the last five years, most of the research into wireless communications has been motivated by its potential role in 6G. As standardization efforts begin in 3GPP this year, we will discover which of the so-called “6G enablers” has attracted the industry’s attention. Probably, only a few new technology components will be introduced in the first 6G networks in 2029, and a few more will be gradually introduced over the next decade. In this post, I will provide some brief predictions on what to expect.
6G Frequency Band
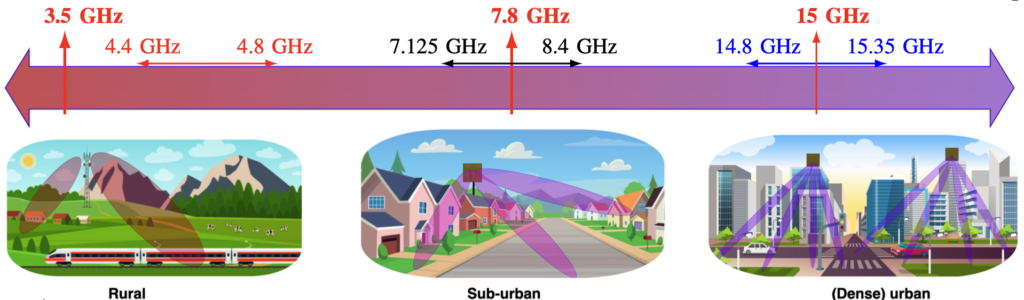
In December 2023, the World Radiocommunication Conference identified three potential 6G frequency bands, which will be analyzed until the next conference in 2027 (see the image below). Hence, the first 6G networks will operate in one of these bands if nothing unforeseen happens. The most interesting new band is around 7.8 GHz, where 650-1275 MHz of spectrum might become available, depending on the country.
This band belongs to the upper mid-band, the previously overlooked range between the sub-7 GHz and the mmWave bands considered in 5G. It has recently been called the golden band since it offers more spectrum than current 5G networks in the 3.5 GHz band and much better propagation conditions than at mmWave frequencies. But honestly, the new spectrum availability is quite underwhelming: It is around twice the amount that 5G networks will already be using in 2029. Hence, we cannot expect any large capacity boost just from introducing these new bands.
Gigantic MIMO arrays
However, the new frequency bands will enable us to deploy many more antenna elements in the same form factor as current antenna arrays. Since the arrays are two-dimensional, the number grows quadratically with the carrier frequency. Hence, we can expect five times as many antennas in the 7.8 GHz band as at 3.5 GHz, which enables spatial multiplexing of five times more data. When combined with twice the amount of spectrum, we can reach an order of magnitude (10×) higher capacity in the first 6G networks than in 5G.
Since the 5G antenna technology is called “Massive MIMO” and 6G will utilize much larger antenna numbers, we need to find a new adjective. I think “Gigantic MIMO“, abbreviated as gMIMO, is a suitable term. The image below illustrates a 0.5 × 0.5 m array with 25 × 25 antenna elements in the 7.8 GHz band. Since practical base stations often have antenna numbers being a power of two, it is likely we will see at least 512 antenna elements in 6G.
During the last few months, my postdocs and I have looked into what the gMIMO technology could realistically achieve in 6G. We have written a magazine-style paper to discuss the upper mid-band in detail, describe how to reach the envisioned 6G performance targets, and explain what deployment practices are needed to utilize the near-field beamfocusing phenomenon for precise communication, localization, and sensing. We also identify five open research challenges, which we recommend you look into if you want to impact the actual 6G standardization and development.
In what ways could we improve cellular-massive-MIMO based 5G? Well, to start with, this technology is already pretty good. But coverage holes, and difficulties to send multiple streams to multi-antenna users because of insufficient channel rank, remain issues.
Perhaps the ultimate solution is distributed MIMO (also known as cell-free massive MIMO). But while this is at heart a powerful technology, installing backhaul seems dreadfully expensive, and achieving accurate phase-alignment for coherent multiuser beamforming on downlink is a difficult technical problem. Another option is RIS – but they have large form factors and require a lot of training and control overhead, and probably, in practice, some form of active filtering to make them sufficiently band-selective.
A different, radically new approach is to deploy large numbers of physically small and cheap wireless repeaters, that receive and instantaneously retransmit signals – appearing as if they were ordinary scatterers in the channel, but with amplification. Repeaters, as such, are deployed today already but only in niche use cases. Could they be deployed at scale, in swarms, within the cells? What would be required of the repeaters, and how well could a repeater-assisted cellular massive MIMO system work, compared to distributed MIMO? What are the fundamental limits of this technology?
At last, some significant new research directions for the wireless PHY community!
I started analyzing reconfigurable intelligent surfaces (RISs) in 2019, just when the hype began in the communication community. I was mostly interested in understanding the fundamentals of this technology because some claims that I found in papers were too good to be true. In 2020, we summarized our thoughts in the paper “Reconfigurable Intelligent Surfaces: Three Myths and Two Critical Questions,” which corrected three misconceptions that flourished then.
More importantly, we identified two open research problems that we found particularly important to solve if the RIS technology should become practically and commercially viable.
The first question was: What is a Convincing Use Case for RIS? The literature was already full of potential use cases; take any communication scenario and add an RIS, and you will improve the system performance by a little. However, the proposed use cases were either too niche-oriented to motivate technology development or aimed at “solving” problems that existing technology (e.g., relays or small cells) could already manage to some extent. A groundbreaking use case of clear commercial value was missing, and I think we have yet to find it.
The second question was: How can we estimate channels and control a RIS in real time? I was skeptical that it would be possible to solve this problem until I saw a demo video from the University of Surrey in late 2020 and participated in a measurement campaign at the Huazhong University of Science and Technology. I then decided to look for a solution together with my research group at KTH.
Real-time reconfigurability is challenging because a typical RIS has hundreds of elements; thus, there are hundreds of channel parameters to estimate every time the channel changes. A plausible solution is to narrow the scope to use cases where the channels can be parametrized efficiently. If the propagation geometry is such that the channel is determined by the same few parameters, regardless of how many RIS elements there are, we can focus on estimating those parameters instead. We realized that array signal processing contains the necessary tools for developing such geometry-based models and algorithms.
We now have a solid solution framework. In the following video, I explain our approach, from the first principles to the solution. The slides were originally prepared for a keynote speech at IEEE CAMSAP 2023 and then fine-tuned for my recent keynote at IEEE SITB 2024.
The academic research into wireless communication is fast-paced, enabled by the fact that one can write a paper in just a few months if it only involves mathematical derivations and computer simulations. This feature can be a strength when it comes to identifying new concepts and developing know-how, but it also leaves a lot of research results unproven in the real world. Even if the math is correct, the underpinning models simplify the physical world. The models can have served us well in the past, but might have to be refined to keep delivering accurate insights as wireless technology becomes more advanced. This is why experimental validation is essential to build credibility behind new wireless functionalities.
Unfortunately, there are many disadvantages to being an experimental researcher in the wireless communication community. It takes longer to gather material for publications, the required hardware equipment makes the research much more expensive, and experimental results are seldom given the recognition they deserve (e.g., when awards and citations are handed out). As a result, theoretical works dominate ComSoc’s scientific journals.
The dominance of purely theoretical contributions means that we can accidentally build an entire house of cards of an emerging concept before we have validated experimentally that the foundation is solid. We can take the pilot contamination phenomenon as an example: hundreds of theoretical papers analyzed its consequences in the last decade and devised algorithms to mitigate it. However, I have not seen any experimental work validating any of it.
Experiments on Reconfigurable Intelligent SurfacesGet Recognition
In recent years, the most hyped new technology is reconfigurable intelligent surfaces (RIS). My research on this topic started five years ago when I became suspicious of the claims and modeling provided in some early works. We addressed these issues in the paper “Reconfigurable Intelligent Surfaces: Three Myths and Two Critical Questions” in 2020, but I remained skeptical of the technology’s maturity until later that year. That is when a group at the University of Surrey published a video showcasing an experimental proof-of-concept in an indoor scenario.
Further experimental results were disseminated right after that. 2024 is a special year: IEEE ComSoc decided to award two of these works with their finest awards for journal publications, thereby recognizing the importance of elevating the technology readiness level (TRL) through validation and field trials.
The IEEE ComSoc Stephen O. Rice Prize went to the paper “RIS-Aided Wireless Communications: Prototyping, Adaptive Beamforming, and Indoor/Outdoor Field Trials“. This paper raised the TRL to 5 by demonstrating the use of the technology in a real WiFi network using existing power measurements for over-the-air RIS configuration. Experiments were made in both indoor and outdoor scenarios. I thank Prof. Haifan Yin and his team at Huazhong University of Science and Technology for involving me in this prototyping effort.
Thanks to experimental works like these, we know that the RIS technology is practically feasible to build, the basic theoretical formulas match reality, and an RIS can provide substantial gains in the intended deployment scenarios. However, if the technology should be used in 6G, we still need to find a compelling business case—this was one of the critical questions posed in my 2020 paper and it remains unanswered.
The PDF is available for free from the publisher’s website, and you can download the simulation code and answers to the exercises from GitHub.
I am amazed at how many people have already downloaded the PDF. However, books should ideally be read in physical format, so we have arranged a special offer for you. Until May 15, you can also buy color-printed copies of the book for only $50 (the list price is $145). To get that price, click on “Buy Book” at the publisher’s website, enter the discount code 919110, and unselect “Add Track & Trace Shipping” (the courier service costs extra).
Here is a video where I explain why we wrote the book and who it is for:
We have now released the 39th episode of the podcast Wireless Future. It has the following abstract:
Massive bandwidths are available in the sub-terahertz bands, but the coverage of a cellular network exploiting those frequencies will be spotty. The 6GTandem project tries to circumvent this issue by developing a dual-frequency system architecture that jointly uses the sub-6 GHz and sub-THz bands. In this episode, Erik G. Larsson and Emil Björnson are visited by Dr. Parisa Aghdam, Technical Lead of 6GTandem and Research Manager at Ericsson. The discussion starts with potential use cases, such as extended reality services in stadiums and connected factories. The conversation then focuses on hardware aspects, such as how to build a distributed antenna system using plastic microwave fibers and amplifiers so that sub-THz signals can be transmitted from many different locations. You can read more about the EU-funded project and its partners at https://horizon-6gtandem.eu/
You can watch the video podcast on YouTube:
You can listen to the audio-only podcast at the following places: