Emerging intelligent reflecting surface (IRS) technology, also known under the names “reconfigurable intelligent surface” and “software-controlled metasurface”, is sometimes marketed as an enabling technology for 6G. How do they work, what are their use cases and how much will they improve wireless access performance at large?
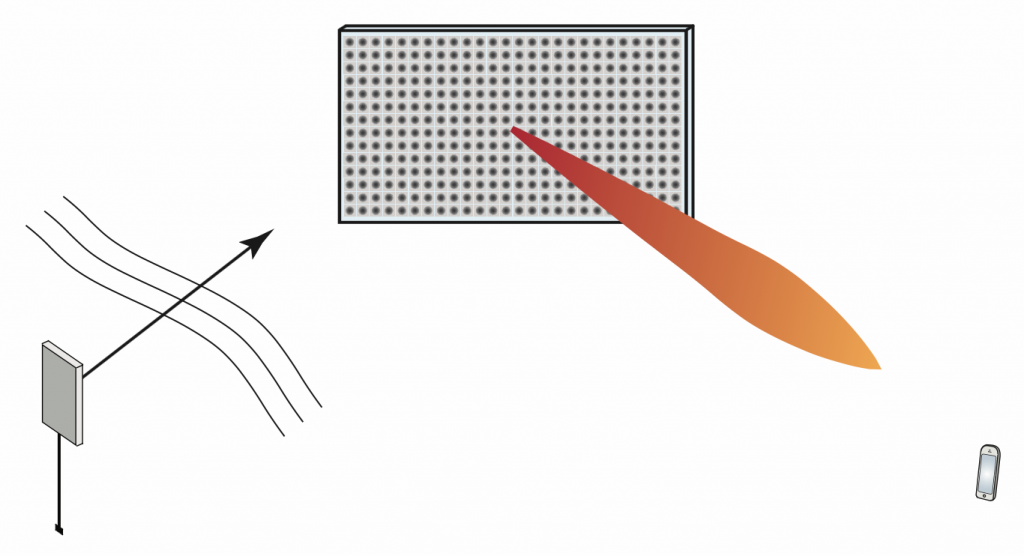
The physical principle of an IRS is that the surface is composed of  atoms, each of which acts as an “intelligent” scatterer: a small antenna that receives and re-radiates without amplification, but with a controllable phase-shift. Typically, an atom is implemented as a small patch antenna terminated with an adjustable impedance. Assuming the phase shifts are properly adjusted, the scattered wavefronts can be made to add up constructively at the receiver. If coupling between the atoms is neglected, the analysis of an IRS essentially entails (i) finding the Green’s function of the source (a sum of spherical waves if close, or a plane wave if far away), (ii) computing the impinging field at each atom, (iii) integrating this field over the surface of each atom to find a current density, (iv) computing the radiated field from each atom using physical-optics approximation, and (v) applying the superposition principle to find the field at the receiver. If the atoms are electrically small, one can approximate the re-radiated field by pretending the atoms are point sources and then the received “signal” is basically a superposition of phase-shifted (as
atoms, each of which acts as an “intelligent” scatterer: a small antenna that receives and re-radiates without amplification, but with a controllable phase-shift. Typically, an atom is implemented as a small patch antenna terminated with an adjustable impedance. Assuming the phase shifts are properly adjusted, the scattered wavefronts can be made to add up constructively at the receiver. If coupling between the atoms is neglected, the analysis of an IRS essentially entails (i) finding the Green’s function of the source (a sum of spherical waves if close, or a plane wave if far away), (ii) computing the impinging field at each atom, (iii) integrating this field over the surface of each atom to find a current density, (iv) computing the radiated field from each atom using physical-optics approximation, and (v) applying the superposition principle to find the field at the receiver. If the atoms are electrically small, one can approximate the re-radiated field by pretending the atoms are point sources and then the received “signal” is basically a superposition of phase-shifted (as  ), amplitude-scaled (as
), amplitude-scaled (as  ) source signals.
) source signals.
A point worth re-iterating is that an atom is a scatterer, not a “mirror”. A more subtle point is that the entire IRS as such, consisting of a collection of scatterers, is itself also a scatterer, not a mirror. “Mirrors” exist only in textbooks, when a plane wave is impinging onto an infinitely large conducting plate (none of which exist in practice). Irrespective of how the IRS is constructed, if it is viewed from far enough away, its radiated field will have a beamwidth that is inversely proportional to its size measured in wavelengths.
Two different operating regimes of IRSs can be distinguished:
1. Both transmitter and receiver are in the far-field of the surface. Then the waves seen at the surface can be approximated as planar; the phase differential from the surface center to its edge is less than a few degrees, say. In this case the phase shifts applied to each atom should be linear in the surface coordinate. The foreseen use case would be to improve coverage, or provide an extra path to improve the rank of a point-to-point MIMO channel. Unfortunately in this case the transmitter-IRS-path loss scales very unfavorably, as  where is the number of meta-atoms in the surface, and the reason is that again, the IRS itself acts as a (large) scatterer, not a “mirror”. Therefore the IRS has to be quite large before it becomes competitive with a standard single-antenna decode-and-forward relay, a simple, well understood technology that can be implemented using already widely available components, at small power consumption and with a small form factor. (In addition, full-duplex technology is emerging and may eventually be combined with relaying, or even massive MIMO relaying.)
where is the number of meta-atoms in the surface, and the reason is that again, the IRS itself acts as a (large) scatterer, not a “mirror”. Therefore the IRS has to be quite large before it becomes competitive with a standard single-antenna decode-and-forward relay, a simple, well understood technology that can be implemented using already widely available components, at small power consumption and with a small form factor. (In addition, full-duplex technology is emerging and may eventually be combined with relaying, or even massive MIMO relaying.)
2. At least one of the transmitter and the receiver is in the surface near-field. Here the plane-wave approximation is no longer valid. The IRS can then either be sub-optimally configured to act as a “mirror”, in which case the phase shifts vary linearly as function of the surface coordinate. Alternatively, it can be configured to act as a “lens”, with optimized phase-shifts, which is typically better. As shown for example in this paper, in the near-field case the path loss scales more favorably than in the far-field case. The use cases for the near-field case are less obvious, but one can think of perhaps indoor environments with users close to the walls and every wall covered by an IRS. Another potential use case that I learned about recently is to use the IRS as a MIMO transmitter: a single-antenna transmitter near an IRS can be jointly configured to act as a MIMO beamforming array.
So how useful will IRS technology be in 6G? The question seems open. Indoor coverage in niche scenarios, but isn’t this an already solved problem? Outdoor coverage improvement, but then (cell-free) massive MIMO seems to be a much better option? Building MIMO transmitters from a single-antenna seems exciting, but is it better than using conventional RF? Perhaps it is for the Terahertz bands, where implementation of coherent MIMO may prove truly challenging, that IRS technology will be most beneficial.
A final point is that nothing requires the atoms in an IRS to be located adjacently to one another, or even to form a surface! But they are probably easier to coordinate if they are in more or less the same place.