In the research on Beyond Massive MIMO systems, a number of new terminologies have been introduced with names such as:
- Reconfigurable reflectarrays;
- Software-controlled metasurfaces;
- Intelligent reflective surfaces.
These are basically the same things (and there are many variations on the three names), which is important to recognize so that the research community can analyze them in a joint manner.
Background
The main concept has its origin in reflectarray antennas, which is a class of directive antennas that behave a bit like parabolic reflectors but can be deployed on a flat surface, such as a wall. More precisely, a reflectarray antenna takes an incoming signal wave and reflects it into a predetermined spatial direction, as illustrated in the following figure:
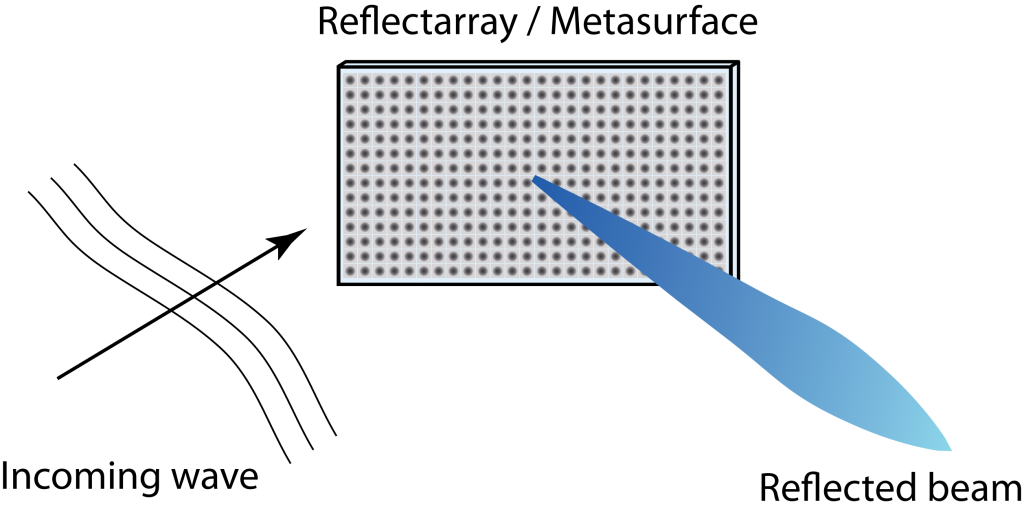
Instead of relying on the physical shape of the antenna to determine the reflective properties (as is the case for parabolic reflectors), a reflectarray consists of many reflective elements that impose element-specific time delays to their reflected signals. These elements are illustrated by the dots on the surface in Figure 1. In this way, the reflected wave is beamformed and the reflectarray can be viewed as a passive MIMO array. The word passive refers to the fact that the radio signal is not generated in the array but elsewhere. Since a given time delay corresponds to a different phase shift depending on the signal’s frequency, reflectarrays are primarily useful for reflecting narrowband signals in a single direction.
Reconfigurability
Reconfigurable reflectarrays can change the time delays of each element to steer the reflected beam in different directions at different points in time. The research on this topic has been going on for decades; the book “Reflectarray Antennas: Analysis, Design, Fabrication, and Measurement” from 2014 by Shaker et al. describes many different implementation concepts and experiments.
Recently, there is a growing interest in reconfigurable reflectarrays from the communication theoretic and signal processing community. This is demonstrated by a series of new overview papers that focus on applications rather than hardware implementations:
- A New Wireless Communication Paradigm through Software-Controlled Metasurfaces by C. Liaskos et al.
- Smart Radio Environments Empowered By Reconfigurable AI Meta-Surfaces: An Idea Whose Time Has Come by M. Di Renzo, et al.
- Towards Smart and Reconfigurable Environment: Intelligent Reflecting Surface Aided Wireless Network by Q. Wu and R. Zhang
- Massive MIMO is a Reality – What is Next? Five Promising Research Directions for Antenna Arrays by E. Björnson et al.
The elements in the reflecting surface in Figure 1 are called meta-atoms or reflective elements in these overview papers. The size of a meta-atom/element is smaller than the wavelength, just as for conventional low-gain antennas. In simple words, we can view an element as an antenna that captures a radio signal, keeps it inside itself for a short time period to create a time-delay, and then radiates the signal again. One can thus view it as a relay with a delay–and-forward protocol. Even if the signals are not amplified by a reconfigurable reflectarray, there is a non-negligible energy consumption related to the control protocols and the reconfigurability of the elements.
It is important to distinguish between reflecting surfaces and the concept of large intelligent surfaces with active radio transmitters/receivers, which was proposed for data transmission and positioning by Hu, Rusek, and Edfors. This is basically an active MIMO array with densely deployed antennas.
What are the prospects of the technology?
The recent overview papers describe a number of potential use cases for reconfigurable reflectarrays (metasurfaces) in wireless networks, such as range extension, improved physical layer security, wireless power transfer, and spatial modulation. From a conceptual perspective, it is indeed an exciting prospect to build future networks where not only the transmitter and receiver algorithms can be optimized, but the propagation environment can be partially controlled.
However, the research on this topic is still in its infancy. It is of paramount importance to demonstrate practically important use cases where reconfigurable reflectarrays are fundamentally better than existing methods. If it should be economically feasible to turn the technology into a commercial reality, we should not look for use cases where a 10% gain can be achieved but rather a 10x or 100x gain. This is what Marzetta demonstrated with Massive MIMO and this is also what it can deliver in 5G.
I haven’t seen any convincing demonstrations of such use cases of reflectarray antennas (metasurfaces) thus far. On the contrary, my new paper “Intelligent Reflecting Surface vs. Decode-and-Forward: How Large Surfaces Are Needed to Beat Relaying?” shows that the new technology can indeed provide range extension, but a basic single-antenna decode-and-forward relay can outperform it unless the surface is very large. There is much left to do on this topic!