
“Open science is just science done right” is a quote from Prof. Jon Tennant in a recent podcast. He is referring to the movement away from the conventionally closed science community where you need to pay to gain access to research results and everyone treats data and simulation code as confidential. Since many funding agencies are requiring open access publishing and open data nowadays, we are definitely moving in the open science direction. But different research fields are at different positions on the scale between fully open and entirely closed science. The machine learning community has embraced open science to a large extent, maybe because the research requires common data sets. When the Nature Machine Intelligence journal was founded, more 3000 researchers signed a petition against its closed access and author fees and promised to not publish in that journal. However, research fields that for decades have been dominated by a few high-impact journals (such as Nature) have not reached as far.
IEEE is the main publisher of Massive MIMO research and has, fortunately, been quite liberal in terms of allowing for parallel publishing. At the time of writing this blog post, the IEEE policy is that an author is allowed to upload the accepted version of their paper on the personal website, the author’s employer’s website, and on arXiv.org. It is more questionable if it is allowed to upload papers in other popular repositories such as ResearchGate – can the ResearchGate profile pages count as personal websites?
It is we as researchers that need to take the steps towards open science. The publishers will only help us under the constraint that they can sustain their profits. For example, IEEE Access was created to have an open access alternative to the traditional IEEE journals, but its quality is no better than non-IEEE journals that have offered open access for a long time. I have published several papers in IEEE Access and although I’m sure that these papers are of good quality, I’ve been quite embarrassed by the poor review processes.
Personally, I try to make all my papers available on arXiv.org and also publish simulation code and data on my GitHub whenever I can, in an effort to support research reproducibility. My reasons for doing this are explained in the following video:
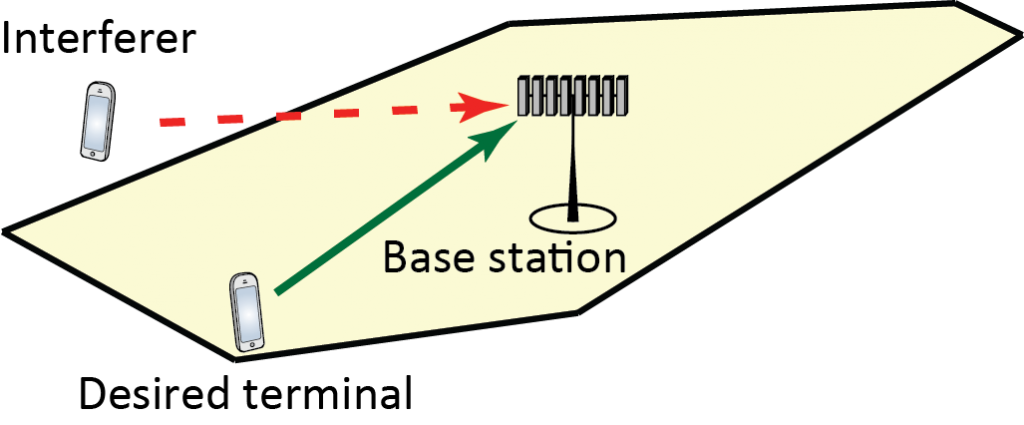
 -antenna base station (BS). The channel vector
-antenna base station (BS). The channel vector  varies over time and frequency in a way that is often modeled as random fading. In each channel coherence blocks, the BS selects a precoding vector
varies over time and frequency in a way that is often modeled as random fading. In each channel coherence blocks, the BS selects a precoding vector  and uses it for downlink transmission. The precoding reduces the multiantenna vector channel to an effective single-antenna scalar channel
and uses it for downlink transmission. The precoding reduces the multiantenna vector channel to an effective single-antenna scalar channel
 and
and  . However, to decode the downlink data in a successful way, it needs to learn the complex scalar channel
. However, to decode the downlink data in a successful way, it needs to learn the complex scalar channel  . The difficulty in learning
. The difficulty in learning  In this case, the BS tries out a set of different precoding vectors from a codebook (e.g., a grid of beams, as shown to the right) by sending one downlink pilot signal through each one of them. The user measures
In this case, the BS tries out a set of different precoding vectors from a codebook (e.g., a grid of beams, as shown to the right) by sending one downlink pilot signal through each one of them. The user measures  . The BS will then transmit data using that precoding vector. During the data transmission,
. The BS will then transmit data using that precoding vector. During the data transmission,  can have any phase, but the user already knows the phase and can compensate for it in the decoding algorithm.
can have any phase, but the user already knows the phase and can compensate for it in the decoding algorithm. In this case, the user transmits a pilot signal in the uplink, which enables the BS to directly estimate the entire channel vector
In this case, the user transmits a pilot signal in the uplink, which enables the BS to directly estimate the entire channel vector  is used for downlink data transmission. The effective channel gain will then be
is used for downlink data transmission. The effective channel gain will then be

 Pilot contamination used to be seen as the key issue with the Massive MIMO technology, but thanks to a large number of scientific papers we now know fairly well how to deal with it. I outlined the main approaches to mitigate pilot contamination in a
Pilot contamination used to be seen as the key issue with the Massive MIMO technology, but thanks to a large number of scientific papers we now know fairly well how to deal with it. I outlined the main approaches to mitigate pilot contamination in a  and is disturbed by noise with power
and is disturbed by noise with power  and interference from another user with power
and interference from another user with power  . By varying the variable
. By varying the variable 

 is due to pilot contamination (it is often called coherent interference) and is proportional to the interference power
is due to pilot contamination (it is often called coherent interference) and is proportional to the interference power  . When the number of antennas is large, it is far better to have more noise during the pilot transmission than more interference!
. When the number of antennas is large, it is far better to have more noise during the pilot transmission than more interference! will remain. The MSE has been used far too often when evaluating pilot decontamination algorithms, and a few papers (I found three while writing this post) did only consider the MSE, which opens the door for questioning their conclusions.
will remain. The MSE has been used far too often when evaluating pilot decontamination algorithms, and a few papers (I found three while writing this post) did only consider the MSE, which opens the door for questioning their conclusions.