
If you are following the 5G news, you might have noticed the many claims from various operators and telecom manufactures of being first with 5G. How can more than one company be first?
One telling example from this week is that on Thursday, Sprint/Nokia/Qualcomm reported about the “First 5G Data Call Using 2.5 GHz” and on Friday, Ericsson/Qualcomm reported about a “5G data call on 2.6 GHz band (…) adding a new frequency band to those successfully tested for commercial deployment.” The difference in carrier frequency is so small that I suppose the same hardware could have been used in both bands; for example, the LTE Massive MIMO product that I wrote about last August is designed for the frequency range 2496-2690 MHz. Yet, there is no contradiction between the two press releases; there are many different frequency bands and 5G features that one can be the first to demonstrate the use of, so we will likely see many more reports like these ones.

The multitude of press releases of this kind is an indicator of: 1) The many tests of soon-to-be-released hardware that are ongoing; 2) The importance for the companies to push out a steady stream of 5G related news.
When it comes to Massive MIMO, Sprint has previously showcased their use of fully digital 64-antenna panels at sub-6 GHz frequencies. In the new press release, they mention that hundreds of such panels were deployed in their network in 2018. Dr. Wen Tong, Head of Wireless Research at Huawei, made a similar claim about China in his keynote at GLOBECOM 2018. These are of course very small numbers compared to the millions of LTE base stations that exist in the world, but it indicates how important Massive MIMO will be in 5G. In fact, there are good reasons to believe that some kind of Massive MIMO technology will be used in almost every 5G base station.

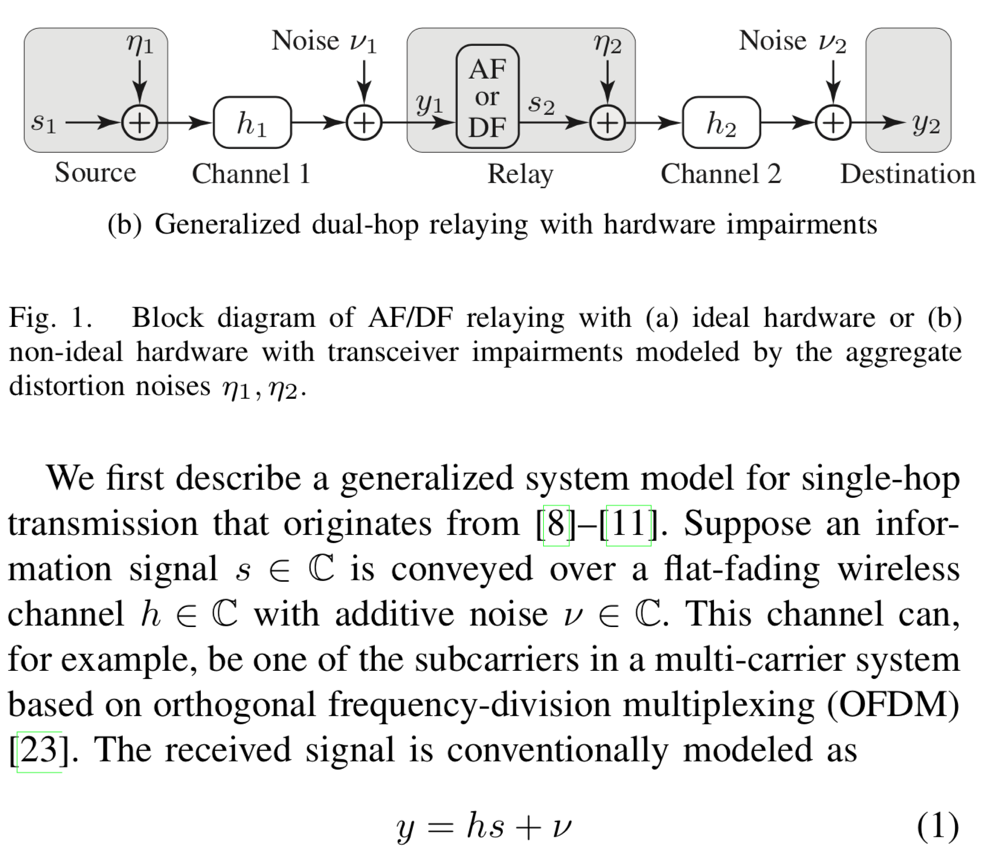


 -antenna base station (BS) serves
-antenna base station (BS) serves  single-antenna users. The large-scale channel gains include pathloss with exponent
single-antenna users. The large-scale channel gains include pathloss with exponent  and shadowing having log-scale standard deviation
and shadowing having log-scale standard deviation  , with the gain between the
, with the gain between the  th BS and the
th BS and the  th user served by a BS of interest denoted by
th user served by a BS of interest denoted by  .
.
 is the gain from the serving BS and
is the gain from the serving BS and  is the share of that BS’s power allocated to user
is the share of that BS’s power allocated to user  .
. , with the proportionality constant ensuring that
, with the proportionality constant ensuring that  . This makes
. This makes  . Moreover, as
. Moreover, as 
 , which makes it valid for arbitrary BS locations.
, which makes it valid for arbitrary BS locations. . Define
. Define  as the solution to
as the solution to  where
where  is the lower incomplete gamma function. For
is the lower incomplete gamma function. For  , in particular,
, in particular,  . Under a uniform power allocation, the CDF of
. Under a uniform power allocation, the CDF of  is available in an explicit form involving the Gauss hypergeometric function
is available in an explicit form involving the Gauss hypergeometric function  (available in MATLAB and Mathematica):
(available in MATLAB and Mathematica):
 ” indicates asymptotic (
” indicates asymptotic ( ) equality,
) equality,  is such that the CDF is continuous, and
is such that the CDF is continuous, and
 :
:

 with CDF
with CDF  readily characterizable from the expressions given earlier. From
readily characterizable from the expressions given earlier. From  , the sum spectral efficiency at the BS of interest can be found as
, the sum spectral efficiency at the BS of interest can be found as  Expressions for the averages
Expressions for the averages ![\bar{C} = \mathbb{E} \big[ C_k \big]](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-a887caab28778e8d91a237bcc86a9f3e_l3.png "Rendered by QuickLaTeX.com") and
and ![\bar{C}_{\scriptscriptstyle \Sigma} = \mathbb{E} \! \left[ C_{\scriptscriptstyle \Sigma} \right]](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-865de5351a43ee6f0405ddb531ed84ee_l3.png "Rendered by QuickLaTeX.com") are further available in the form of single integrals.
are further available in the form of single integrals.
 . For the special case of
. For the special case of 

 ,
,  and
and  –
– dB with the analysis. The behaviors with these typical outdoor values of
dB with the analysis. The behaviors with these typical outdoor values of 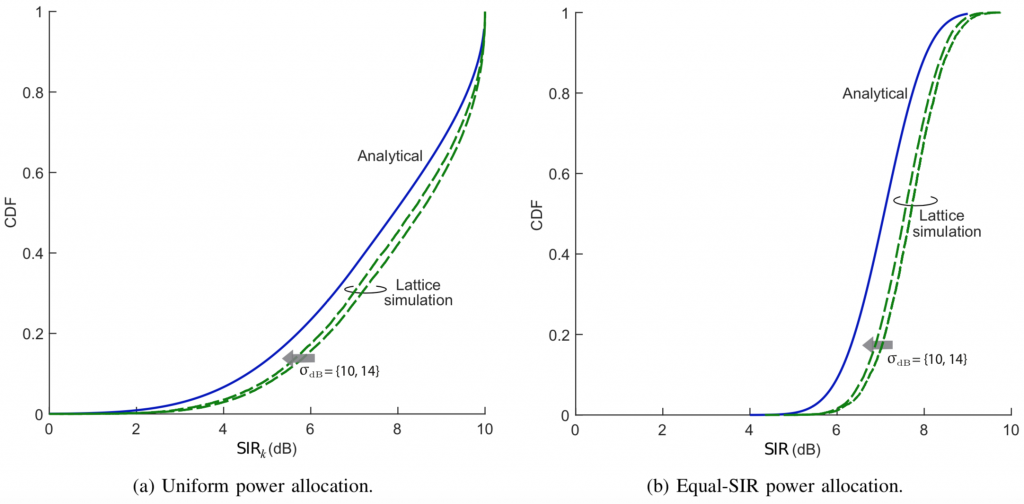
 and
and  . Figs. 2a-2b compare the simulations for
. Figs. 2a-2b compare the simulations for  dB with the analysis, and the agreement is now complete. The simulated average spectral efficiency with a uniform power allocation is
dB with the analysis, and the agreement is now complete. The simulated average spectral efficiency with a uniform power allocation is  b/s/Hz/user while (2) gives
b/s/Hz/user while (2) gives  b/s/Hz/user.
b/s/Hz/user.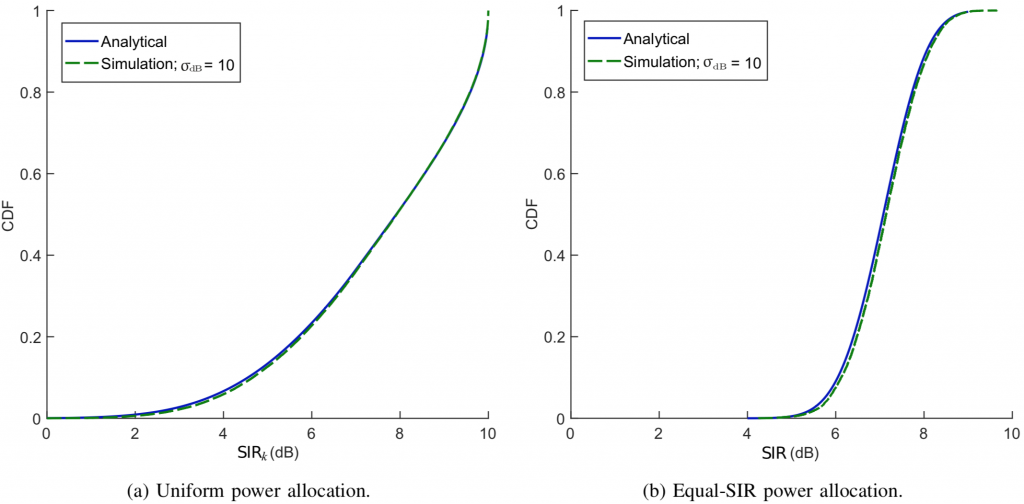
 –
– with very conservative premises) where these effects are rather minor, and the analysis is hence applicable.
with very conservative premises) where these effects are rather minor, and the analysis is hence applicable.