
One reason for why capacity lower bounds are so useful is that they are accurate proxies for link-level performance with modern coding. But this fact, well known to information and coding theorists, is often contested by practitioners. I will discuss some possible reasons for that here.
The recipe is to compute the capacity bound, and depending on the code blocklength, add a dB or a few, to the required SNR. That gives the link performance prediction. The coding literature is full of empirical results, showing how far from capacity a code of a given block length is for the AWGN channel, and this gap is usually not extremely different for other channel models – although, one should always check this.
But there are three main caveats with this:
- First, the capacity bound, or the “SINR” that it often contains, must be information-theoretically correct. A great deal of papers get this wrong. Emil explained in his blog post last week some common errors. The recommended approach is to map the channel onto one of the canonical cases in Figure 2.9 in Fundamentals of Massive MIMO, verify that the technical conditions are satisfied, and use the corresponding formula.
- When computing expressions of the type E[log(1+”SINR”)], then the average should be taken over all quantities that are random within the duration of a codeword. Typically, this means averaging over the randomness incurred by the noise, channel estimation errors, and in many cases the small-scale fading. All other parameters must be kept fixed. Typically, user positions, path losses, shadow fading, scheduling and pilot assignments, are fixed, so the expectation is conditional on those. (Yet, the interference statistics may vary substantially, if other users are dropping in and out of the system.) This in turn means that many “drops” have to be generated, where these parameters are drawn at random, and then CDF curves with respect to that second level of randomness needs be computed (numerically).Think of the expectation E[log(1+”SINR”)] as a “link simulation”. Every codeword sees many independent noise realizations, and typically small-scale fading realizations, but the same realization of the user positions. Also, often, neat (and tight) closed-form bounds on E[log(1+”SINR”)] are available.
- Care is advised when working with relatively short blocks (less than a few hundred bits) and at rates close to the constrained capacity with the foreseen modulation format. In this case, many of the “standard” capacity bounds become overoptimistic.As a rule of thumb, compare the capacity of an AWGN channel with the constrained capacity of the chosen modulation at the spectral efficiency of interest, and if the gap is small, the capacity bounds will be useful. If not, then reconsider the choice of modulation format! (See also homework problem 1.4.)
How far are the bounds from the actual capacity typically? Nobody knows, but there are good reasons to believe they are extremely close. Here (Figure 1) is a nice example that compares a decoder that uses the measured channel likelihood, instead of assuming a Gaussian (which is implied by the typical bounding techniques). From correspondence with one of the authors: “The dashed and solid lines are the lower bound obtained by Gaussianizing the interference, while the circles are the rate achievable by a decoder exploiting the non-Gaussianity of the interference, painfully computed through days-long Monte-Carlo. (This is not exactly the capacity, because the transmit signals here are Gaussian, so one could deviate from Gaussian signaling and possibly do slightly better — but the difference is imperceptible in all the experiments we’ve done.)”
Concerning Massive MIMO and its capacity bounds, I have met for a long time with arguments that these capacity formulas aren’t useful estimates of actual performance. But in fact, they are: In one simulation study we were less than one dB from the capacity bound by using QPSK and a standard LDPC code (albeit with fairly long blocks). This bound accounts for noise and channel estimation errors. Such examples are in Chapter 1 of Fundamentals of Massive MIMO, and also in the ten-myth paper:
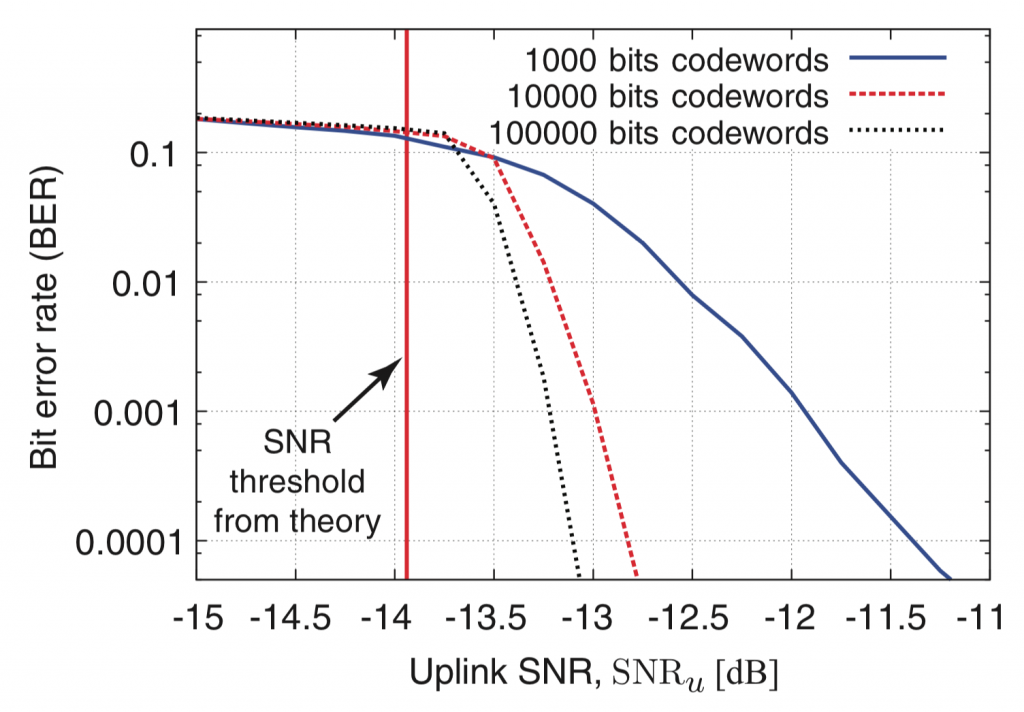
(I wrote the simulation code, and can share it, in case anyone would want to reproduce the graphs.)
So in summary, while capacity bounds are sometimes done wrong; when done right they give pretty good estimates of actual link performance with modern coding.
(With thanks to Angel Lozano for discussions.)
Hi
Thank you very much for the new post,
I got a little bit confused about “2.”,
if I understand correctly, first we should make an average with respect to variables of the first level of randomness that we have for the input-output of the system, given the variables of the second level of randomness, which are constant within the particular intervals of interest. Then, you explained that the CDF curves of the second level of randomness variables can be used to evaluate the data-rates.
What I don’t understand, is that why we can’t make an average for the second level of randomness instead of CDF plot…?
For instance, I also see in “Massive MIMO With Max-Min Power Control in Line-of-Sight Propagation Environment”, that they use the CDF plot for the SINR evaluation of LOS scenarios (Fig 3. and 4.), and not the average.
Best Regards,
Ashkan
Thanks for this very interesting post that propounds the practical relevance of carefully modeled capacity bounds.
I would like to point out one caveat in the description of the second point ‘2.’:
Although it is true that the expectation in E[log(1+”SINR”)] is over the quantities that are random within the duration of a codeword (such as the small-scale channel features), it does not include the averaging over ‘the randomness incurred by noise (AWGN)’ because that is already subsumed in the mutual information form log(1+”SINR”). Specifically, for a given “SINR” value, i.e., with the large- and small-scale channel features conditioned upon,
\log(1+”SINR”) = I(s, \sqrt{“SINR”} \, s + z)
with z being AWGN and the signal s being Gaussian as well. This mutual information involves the expectation over the ‘the randomness incurred by noise (AWGN)’.
Thank you for your comment. This is a subtle point. The noise does not have to be Gaussian; all that is needed is that some technical conditions are satisfied (see the book, Section 2.3.5). The log(1+…) appears as a result of a conditional entropy maximization, which happens to occur when a certain conditional probability density is Gaussian.
Dear Prof. Erik,
Could you please send me the simulation code of Fig. 1 through email? I wanna reproduce this graph.
The code is available at https://github.com/emilbjornson/massive-MIMO-myths/tree/master/simulationFigure3