For the last five years, most of the research into wireless communications has been motivated by its potential role in 6G. As standardization efforts begin in 3GPP this year, we will discover which of the so-called “6G enablers” has attracted the industry’s attention. Probably, only a few new technology components will be introduced in the first 6G networks in 2029, and a few more will be gradually introduced over the next decade. In this post, I will provide some brief predictions on what to expect.
6G Frequency Band
In December 2023, the World Radiocommunication Conference identified three potential 6G frequency bands, which will be analyzed until the next conference in 2027 (see the image below). Hence, the first 6G networks will operate in one of these bands if nothing unforeseen happens. The most interesting new band is around 7.8 GHz, where 650-1275 MHz of spectrum might become available, depending on the country.
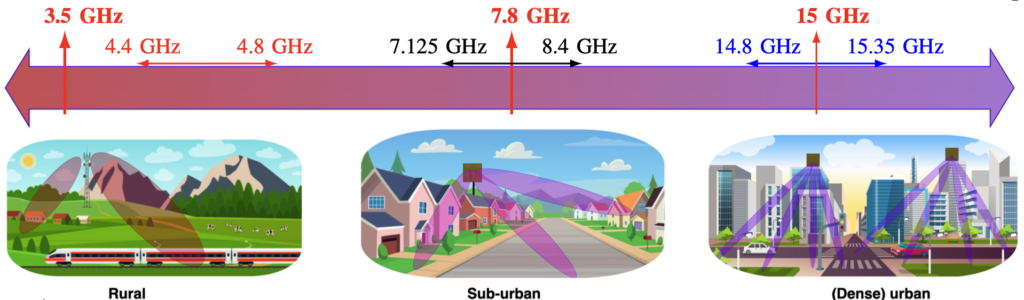
This band belongs to the upper mid-band, the previously overlooked range between the sub-7 GHz and the mmWave bands considered in 5G. It has recently been called the golden band since it offers more spectrum than current 5G networks in the 3.5 GHz band and much better propagation conditions than at mmWave frequencies. But honestly, the new spectrum availability is quite underwhelming: It is around twice the amount that 5G networks will already be using in 2029. Hence, we cannot expect any large capacity boost just from introducing these new bands.
Gigantic MIMO arrays
However, the new frequency bands will enable us to deploy many more antenna elements in the same form factor as current antenna arrays. Since the arrays are two-dimensional, the number grows quadratically with the carrier frequency. Hence, we can expect five times as many antennas in the 7.8 GHz band as at 3.5 GHz, which enables spatial multiplexing of five times more data. When combined with twice the amount of spectrum, we can reach an order of magnitude (10×) higher capacity in the first 6G networks than in 5G.
Since the 5G antenna technology is called “Massive MIMO” and 6G will utilize much larger antenna numbers, we need to find a new adjective. I think “Gigantic MIMO“, abbreviated as gMIMO, is a suitable term. The image below illustrates a 0.5 × 0.5 m array with 25 × 25 antenna elements in the 7.8 GHz band. Since practical base stations often have antenna numbers being a power of two, it is likely we will see at least 512 antenna elements in 6G.
During the last few months, my postdocs and I have looked into what the gMIMO technology could realistically achieve in 6G. We have written a magazine-style paper to discuss the upper mid-band in detail, describe how to reach the envisioned 6G performance targets, and explain what deployment practices are needed to utilize the near-field beamfocusing phenomenon for precise communication, localization, and sensing. We also identify five open research challenges, which we recommend you look into if you want to impact the actual 6G standardization and development.
You can download the paper here: Emil Björnson, Ferdi Kara, Nikolaos Kolomvakis, Alva Kosasih, Parisa Ramezani, and Murat Babek Salman, “Enabling 6G Performance in the Upper Mid-Band Through Gigantic MIMO,” arXiv:2407.05630.