In the last decade, the research on wireless communications has been strongly focused on the development of 5G. Plenty of papers have started with sentences of the kind: “We consider X, which is a promising method that can greatly improve Y in 5G.” For example, X might be Massive MIMO and Y might be the spectral efficiency. We now know which physical-layer methods made it into the first release of the 5G standard, and which did not. It remains to be seen which methods will actually be used in practice and how large performance improvements 5G can deliver.
There is no doubt that the 5G research has been successful. However, it remains is to improve the developed methods to bridge the gap between the simplifying models and assumptions considered in academia and the practical conditions faced by the industry. Although new scientific papers appear on arXiv.org almost every day, few of them focus on these practically important aspects of the 5G development. Instead, minor variations on well-studied problems dominate and the models are the same simplified ones as ten years ago. We seem to be stuck in doing the same things that led to important advances at the beginning of the 2010s, although we have already solved most problems that can be solved using such simple models. This is why I think we need to revitalize the research!
Two concrete examples
The following two examples explain what I mean.
Example 1: Why would we need more papers on Massive MIMO with uncorrelated Rayleigh fading channels and maximum ratio (MR) processing? We already know that practical channels are spatially correlated and other processing methods are vastly superior to MR while having practically affordable complexity.
Example 2: Why would we need more papers on hybrid beamforming design for flat-fading channels? We already know that the hybrid architecture is only meaningful in wideband mmWave communications, in which case the channels feature frequency-selective fading. The generalization is non-trivial since it is mainly under frequency-selective conditions that the weaknesses/challenges of the hybrid approach appear.
I think that the above-mentioned simplifications were well motivated in the early 2010s when many of the seminal papers on Massive MIMO and mmWave communications appeared. It is usually easier to reach ambitious research goals by taking small steps towards them. It is acceptable to make strong simplifications in the first steps, to achieve the analytical tractability needed to develop a basic intuition and understanding. The later steps should, however, gradually move toward more realistic assumptions that also makes the analysis less tractable. We must continuously question if the initial insights apply also under more practical conditions or if they were artifacts of the initial simplifications.
Unfortunately, this happened far too seldom in the last decade. Our research community tends to prioritize analytical tractability over realistic models. If a model has been used in prior work, it can often be reused in new papers without being questioned by the reviewers. When I review a paper and question the system model, the authors usually respond with a list of previous papers that use the same model, rather than the theoretical motivation that I would like to see.
It seems to be far easier to publish papers with simple models that enable derivation of analytical “closed-form” expressions and development of “optimal” algorithms, than to tackle more realistic but challenging models where these things cannot be established. The two examples above are symptoms of this problem. We cannot continue in this way if we want to keep the research relevant in this new decade. Massive MIMO and mmWave communications will soon be mainstream technologies!
Entering a new decade
The start of the 2020s is a good time for the research community to start over and think big. Massive MIMO was proposed in a paper from 2010 and initially seemed too good to be true, possibly due to the simplicity of the models used in the early works. In a paper that appeared in 2015, we identified ten “myths” that had flourished when people with a negative attitude against the technology tried to pinpoint why it wouldn’t work in practice. Today – a decade after its inception – Massive MIMO is a key 5G technology and has even become a marketing term used by cellular operators. The US operator Sprint has reported that the first generation of Massive MIMO base stations improve the spectral efficiency by around 10x in their real networks.
I believe the history will repeat itself during this decade. The research into the next big physical layer technology will take off this year – we just don’t know what it will be. There are already plenty of non-technical papers that try to make predictions, so the quota for such papers is already filled. I’ve written one myself entitled “Massive MIMO is a Reality – What is Next? Five Promising Research Directions for Antenna Arrays”. What we need now are visionary technical papers (like the seminal Massive MIMO paper by Marzetta) that demonstrate mathematically how a new technology can achieve ten-fold performance improvements over the state-of-the-art, for example, in terms of spectral efficiency, reliability, latency, or some other relevant metric. Maybe one or two of the research directions listed in my paper will be at the center of 6G. Much research work remains before we can know, thus this is the right time to explore a wide range of new ideas.
The start of a new decade is a good time for the research community to start over and to think big. Massive MIMO was proposed in a paper from 2010 and initially seemed too good to be true, possibly due to the simplicity of the system models used in the early works. In a paper that appeared in 2015, we identified ten “myths” that had flourished when people tried to pinpoint why Massive MIMO wouldn’t work in practice. Today – a decade after its inception – Massive MIMO is a key 5G technology that has even become a marketing term used by cellular operators. It has been shown to improve the spectral efficiency by 10x in real networks.
I believe that the same procedure will repeat itself during this decade. The research into the next big physical layer technology will take off this year – we just don’t know what it will be. There are already plenty of non-technical papers that try to make predictions, so that quota has already been filled. I’ve written one myself entitled “Massive MIMO is a Reality – What is Next? Five Promising Research Directions for Antenna Arrays”. However, what we really need is visionary technical papers (like the seminal Massive MIMO paper by Marzetta) that demonstrate how we can actually achieve, say, ten-fold performance improvements over the state-of-the-art, concerning spectral efficiency, reliability, latency, or some other relevant metric. Maybe one or two of the research directions listed in my paper will become the main thing in 6G – much further work is needed before we can know.
Five ways to revitalize the research
To keep the wireless communication research relevant, we should stop considering minor variations on previously solved problems and instead focus either on implementation aspects of 5G or on basic research into entirely new methods that might eventually play a role in 6G. In both cases, I have the following five recommendations for how we can conduct more efficient and relevant research in this new decades.
1. We may start the research on new topics by using simplified models that are analytically tractable, but we must not get stuck in using those models. A beautiful analysis obtained with an unrealistic model might cause more confusion than it generates new practical insights. Just remember how a lot of Massive MIMO research focused on the pilot contamination problem, just because it happened to be the asymptotically limiting factor when using simplified models, while it is not the case in general.
2. We must be more respectful towards the underlying physics, particularly, electromagnetic theory. We cannot continue normalizing the pathloss variables or guesstimate how they can be computed. When developing a new technology, we must first get the basic models right. Otherwise we risk making fundamental mistakes and – even worse – trick others into repeating those mistakes for years to come. I covered the danger of normalization in a previous blog post.
3. We must not forget about previous methods when evaluating new methods but think carefully about what the true state-of-the-art is. For example, if we want to improve the performance of a cellular network by adding new equipment, we must compare it to existing equipment that could alternatively been added. For example, I covered the importance of comparing intelligent reflecting surfaces with relays in a previous blog post.
4. We must make sure new algorithms are reproducible and easily comparable, so that every paper is making useful progress. This can be achieved by publishing simulation code alongside papers and evaluating new algorithms in the same setup as previous algorithms. We might take inspiration from the machine learning field where ImageNet is a common benchmark.
5. We must not take the correctness of models and results in published papers for granted. This is particularly important nowadays when new IEEE journals with very short review times are getting traction. Few scientific experts can promise to make a proper review of a full-length paper in just seven days; thus, many reviews will be substandard. This is a step in the wrong direction and can severely reduce the quality and trustworthiness of published papers.
Let us all make an effort to revitalize the research methodology and selection of research problems to solve in the 2020s. If you have further ideas please share them in the comment field!

 in the complex baseband can be divided into two parts:
in the complex baseband can be divided into two parts:
 is the magnitude of the direct path between the transmitter and receiver and
is the magnitude of the direct path between the transmitter and receiver and ![\theta \in [0,2\pi]](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-e70126963911574a22ab8afc7da04ca9_l3.png "Rendered by QuickLaTeX.com") is the corresponding phase shift. The second part,
is the corresponding phase shift. The second part,  , represents all the scattered paths. This part is separated from the direct path since it consists of many paths, each being of roughly the same strength but substantially weaker than the direct path. It is modeled by Rayleigh fading, which implies
, represents all the scattered paths. This part is separated from the direct path since it consists of many paths, each being of roughly the same strength but substantially weaker than the direct path. It is modeled by Rayleigh fading, which implies  . The complex Gaussian distribution is motivated by the
. The complex Gaussian distribution is motivated by the  of the channel coefficient is
of the channel coefficient is  , which depends on the magnitude
, which depends on the magnitude  and the variance
and the variance  of the scattering.
of the scattering. , because the magnitude removes phases and
, because the magnitude removes phases and  are equally distributed. Hence, it is common to omit
are equally distributed. Hence, it is common to omit  as a deterministic constant that is perfectly known at the receiver. I have done this myself in several papers, including
as a deterministic constant that is perfectly known at the receiver. I have done this myself in several papers, including  goes to infinity. Marzetta’s
goes to infinity. Marzetta’s  . In these papers, the signal-to-noise ratio (SNR) grows linearly with
. In these papers, the signal-to-noise ratio (SNR) grows linearly with  (except when pilot contamination
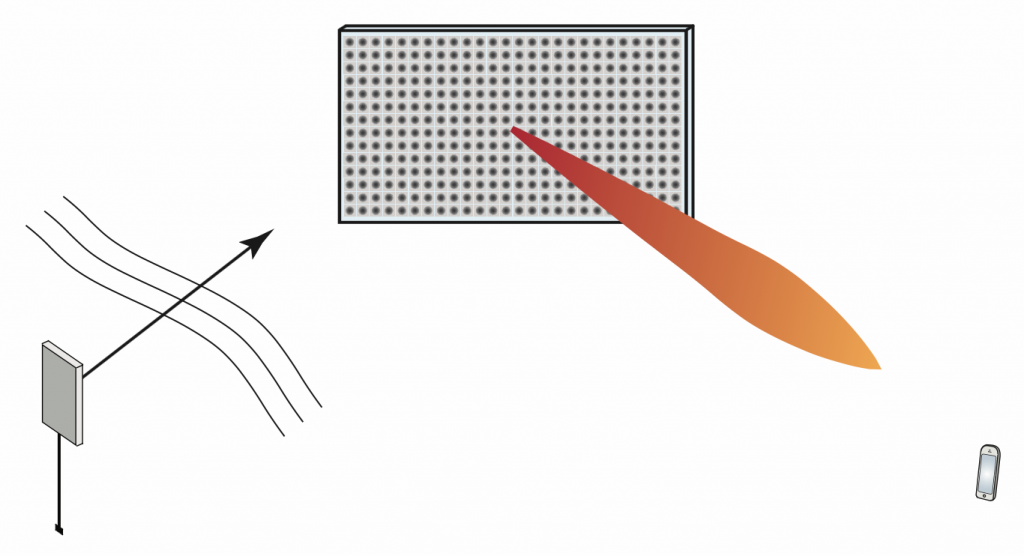
(except when pilot contamination  grid. Such an array is illustrated in Figure 1.
grid. Such an array is illustrated in Figure 1.
 atoms, each of which acts as an “intelligent” scatterer: a small antenna that receives and re-radiates without amplification, but with a controllable phase-shift. Typically, an atom is implemented as a small patch antenna terminated with an adjustable impedance. Assuming the phase shifts are properly adjusted, the
atoms, each of which acts as an “intelligent” scatterer: a small antenna that receives and re-radiates without amplification, but with a controllable phase-shift. Typically, an atom is implemented as a small patch antenna terminated with an adjustable impedance. Assuming the phase shifts are properly adjusted, the  ), amplitude-scaled (as
), amplitude-scaled (as  ) source signals.
) source signals. where
where