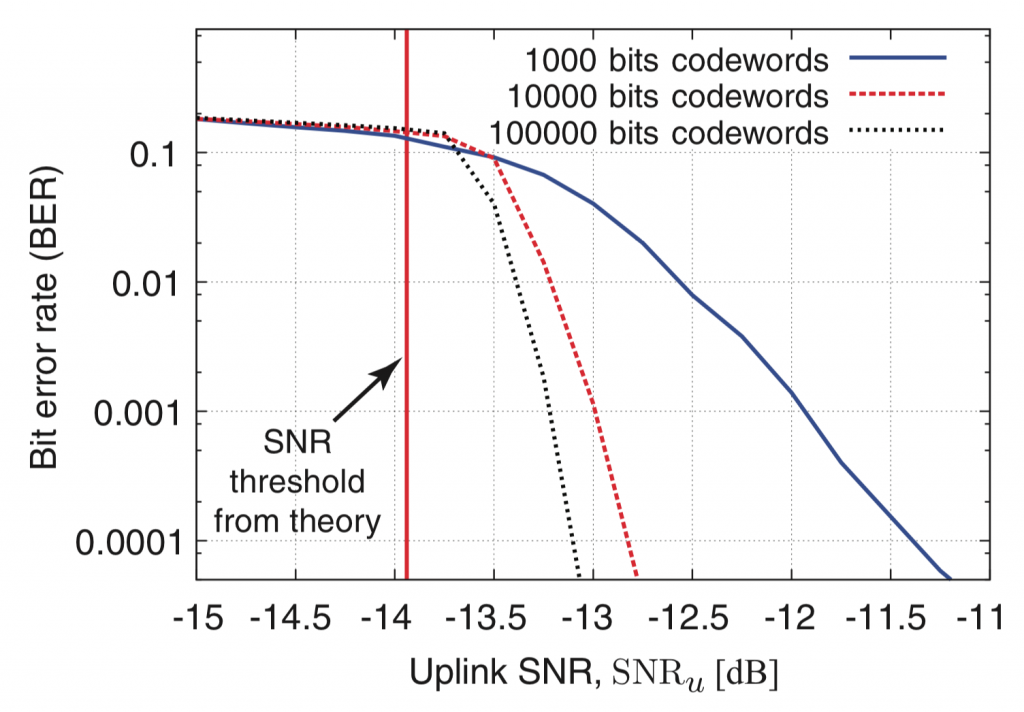
The signal-to-noise ratio (SNR) generally depends on the transmit power, channel gain, and noise power:

Since the spectral efficiency (bit/s/Hz) and many other performance metrics of interest depend on the SNR, and not the individual values of the three parameters, it is a common practice to normalize one or two of the parameters to unity. This habit makes it easier to interpret performance expressions, to select reasonable SNR ranges, and to avoid mistakes in analytical derivations.
There are, however, situations when the absolute value of the transmitted/received signal power matters, and not the relative value with respect to the noise power, as measured by the SNR. In these situations, it is easy to make mistakes if you use normalized parameters. I see this type of errors far too often, both as a reviewer and in published papers. I will give some specific examples below, but I won’t tell you who has made these mistakes, to not point the finger at anyone specifically.
Wireless energy transfer
Electromagnetic radiation can be used to transfer energy to wireless receivers. In such wireless energy transfer, it is the received signal energy that is harvested by the receiver, not the SNR. Since the noise power is extremely small, the SNR is (at least) a billion times larger than the received signal power. Hence, a normalization error can lead to crazy conclusions, such as being able to transfer energy at a rate of 1 W instead of 1 nW. The former is enough to keep a wireless transceiver on continuously, while the latter requires you to harvest energy for a long time period before you can turn the transceiver on for a brief moment.
Energy efficiency
The energy efficiency (EE) of a wireless transmission is measured in bit/Joule. The EE is computed as the ratio between the data rate (bit/s) and the power consumption (Watt=Joule/s). While the data rate depends on the SNR, the power consumption does not. The same SNR value can be achieved over a long propagation distance by using high transmit power or over a short distance by using a low transmit power. The EE will be widely different in these cases. If a “normalized transmit power” is used instead of the actual transmit power when computing the EE, one can get EEs that are one million times smaller than they should be. As a rule-of-thumb, if you compute things correctly, you will get EE numbers in the range of 10 kbit/Joule to 10 Mbit/Joule.
Noise power depends on the bandwidth
The noise power is proportional to the communication bandwidth. When working with a normalized noise power, it is easy to forget that a given SNR value only applies for one particular value of the bandwidth.
Some papers normalize the noise variance and channel gain, but then make the SNR equal to the unnormalized transmit power (measured in W). This may greatly overestimate the SNR, but the achievable rates might still be in the reasonable range if you operate the system in an interference-limited regime.
Some papers contain an alternative EE definition where the spectral efficiency (bit/s/Hz) is divided by the power consumption (Joule/s). This leads to the alternative EE unit bit/Joule/Hz. This definition is not formally wrong, but gives the misleading impression that one can multiply the EE value with any choice of bandwidth to get the desired number of bit/Joule. That is not the case since the SNR only holds for one particular value of the bandwidth.
Knowing when to normalize
In summary, even if it is convenient to normalize system parameters in wireless communications, you should only do it if you understand when normalization is possible and when it is not. Otherwise, you can make embarrassing mistakes, such as submitting a paper where the results are six orders of magnitude wrong. And, unfortunately, there are several such papers that have been published and these create a bad circle by tricking others into making the same mistakes.


 is the number of base-station antennas,
is the number of base-station antennas,  is the number of spatially multiplexed users,
is the number of spatially multiplexed users, ![$c_{ \textrm{\tiny CSI}} \in [0,1]$](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-638fe579c728859336f107711790c035_l3.png "Rendered by QuickLaTeX.com") is the quality of the channel estimates, and
is the quality of the channel estimates, and  is the number of channel uses per channel coherence block. For simplicity, I have assumed the same pathloss for all the users. The variable
is the number of channel uses per channel coherence block. For simplicity, I have assumed the same pathloss for all the users. The variable  is the nominal signal-to-noise ratio (SNR) of a user, achieved when
is the nominal signal-to-noise ratio (SNR) of a user, achieved when  . Eq. (1) is a rigorous lower bound on the sum capacity, achieved under the assumptions of maximum ratio precoding, i.i.d. Rayleigh fading channels, and equal power allocation. With better processing schemes, one can achieve substantially higher performance.
. Eq. (1) is a rigorous lower bound on the sum capacity, achieved under the assumptions of maximum ratio precoding, i.i.d. Rayleigh fading channels, and equal power allocation. With better processing schemes, one can achieve substantially higher performance.
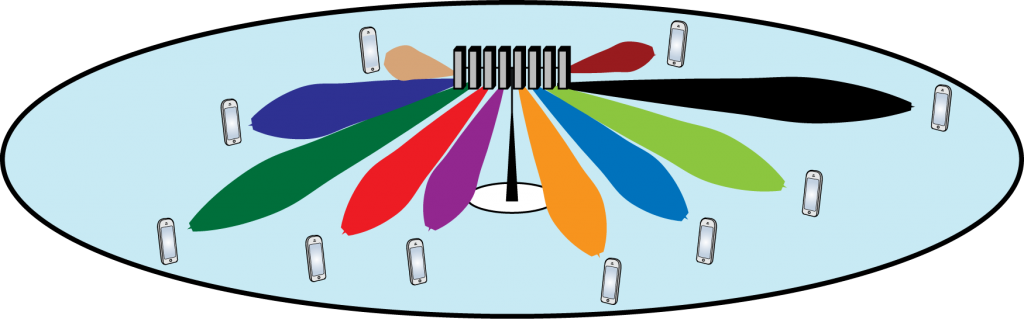
 and, hence, I am a bit concerned that the industry will be disappointed with the gains that they will obtain from such beamforming in 5G.
and, hence, I am a bit concerned that the industry will be disappointed with the gains that they will obtain from such beamforming in 5G. stays constant, then the spectral efficiency will grow linearly with the number of users. Note that the same transmit power is divided between the
stays constant, then the spectral efficiency will grow linearly with the number of users. Note that the same transmit power is divided between the  and
and  , the spectral efficiency will become 5.6 bit/s/Hz. This is the gain from beamforming. If we also increase the number of users to
, the spectral efficiency will become 5.6 bit/s/Hz. This is the gain from beamforming. If we also increase the number of users to  users, we will get 32 bit/s/Hz. This is the gain from spatial multiplexing. Clearly, the largest gains come from spatial multiplexing and adding many antennas is a necessary way to facilitate such multiplexing.
users, we will get 32 bit/s/Hz. This is the gain from spatial multiplexing. Clearly, the largest gains come from spatial multiplexing and adding many antennas is a necessary way to facilitate such multiplexing.