
The hype around machine learning, particularly deep learning, has spread over the world. It is not only affecting engineers but also philosophers and government agencies, which try to predict what implications machine learning will have on our society.
When the initial excitement has subsided, I think machine learning will be an important tool that many engineers will find useful, alongside more classical tools such as optimization theory and Fourier analysis. I have spent the last two years thinking about what role deep learning can have in the field of communications. This field is rather different from other areas where deep learning has been successful: We deal with man-made systems that have designed based on rigorous theory to operate close to the fundamental performance limits, for example, the Shannon capacity. Hence, at first sight, there seems to be little room for improvement.
I have nevertheless identified two main applications of supervised deep learning in the physical layer of communication systems: 1) algorithmic approximation and 2) function inversion.
You can read about them in my recent survey paper “Two Applications of Deep Learning in the Physical Layer of Communication Systems” or watch the following video:
In the video, I’m exemplifying the applications through two recent papers where we applied deep learning to improve Massive MIMO systems. Here are links to those papers:
Trinh Van Chien, Emil Björnson, Erik G. Larsson, “Sum Spectral Efficiency Maximization in Massive MIMO Systems: Benefits from Deep Learning,” IEEE International Conference on Communications (ICC), 2019.
Özlem Tugfe Demir, Emil Björnson, “Channel Estimation in Massive MIMO under Hardware Non-Linearities: Bayesian Methods versus Deep Learning,” IEEE Open Journal of the Communications Society, 2020.
 atoms, each of which acts as an “intelligent” scatterer: a small antenna that receives and re-radiates without amplification, but with a controllable phase-shift. Typically, an atom is implemented as a small patch antenna terminated with an adjustable impedance. Assuming the phase shifts are properly adjusted, the
atoms, each of which acts as an “intelligent” scatterer: a small antenna that receives and re-radiates without amplification, but with a controllable phase-shift. Typically, an atom is implemented as a small patch antenna terminated with an adjustable impedance. Assuming the phase shifts are properly adjusted, the  ), amplitude-scaled (as
), amplitude-scaled (as  ) source signals.
) source signals. where
where 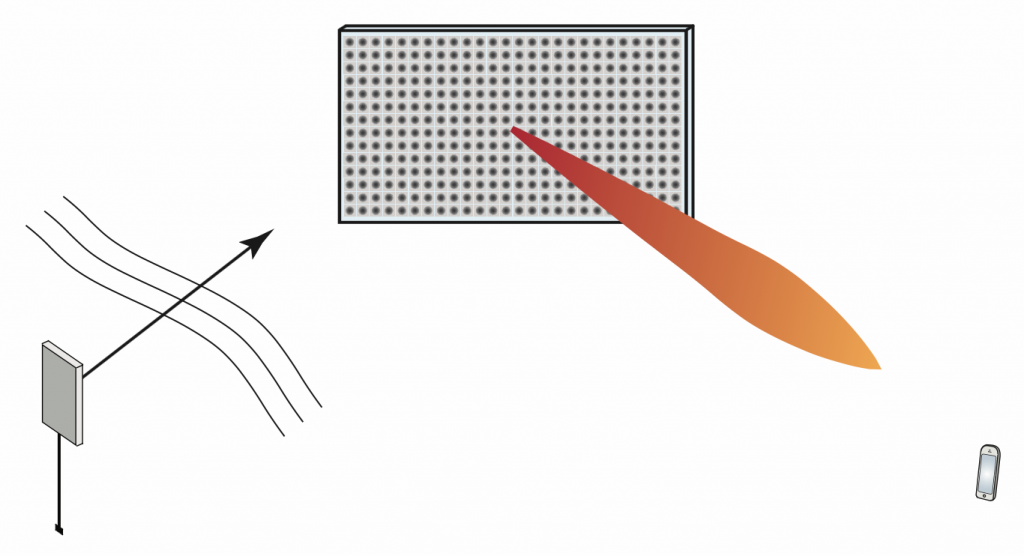
 is
is
 , the wavelength is
, the wavelength is  , and the propagation distance is
, and the propagation distance is  . This formula shows that the received power is proportional to the wavelength and, thus, will be smaller when we increase the carrier frequency; that is, the received power is lower at 60 GHz (
. This formula shows that the received power is proportional to the wavelength and, thus, will be smaller when we increase the carrier frequency; that is, the received power is lower at 60 GHz ( mm) than at 3 GHz (
mm) than at 3 GHz ( cm). But there is an important catch: the dependence on
cm). But there is an important catch: the dependence on 
 , we can instead write the received signal in (1) as
, we can instead write the received signal in (1) as
 , as exemplified in (2), in practice we will need to use arrays of multiple antennas in mmWave bands to achieve the same total antenna area
, as exemplified in (2), in practice we will need to use arrays of multiple antennas in mmWave bands to achieve the same total antenna area  from an
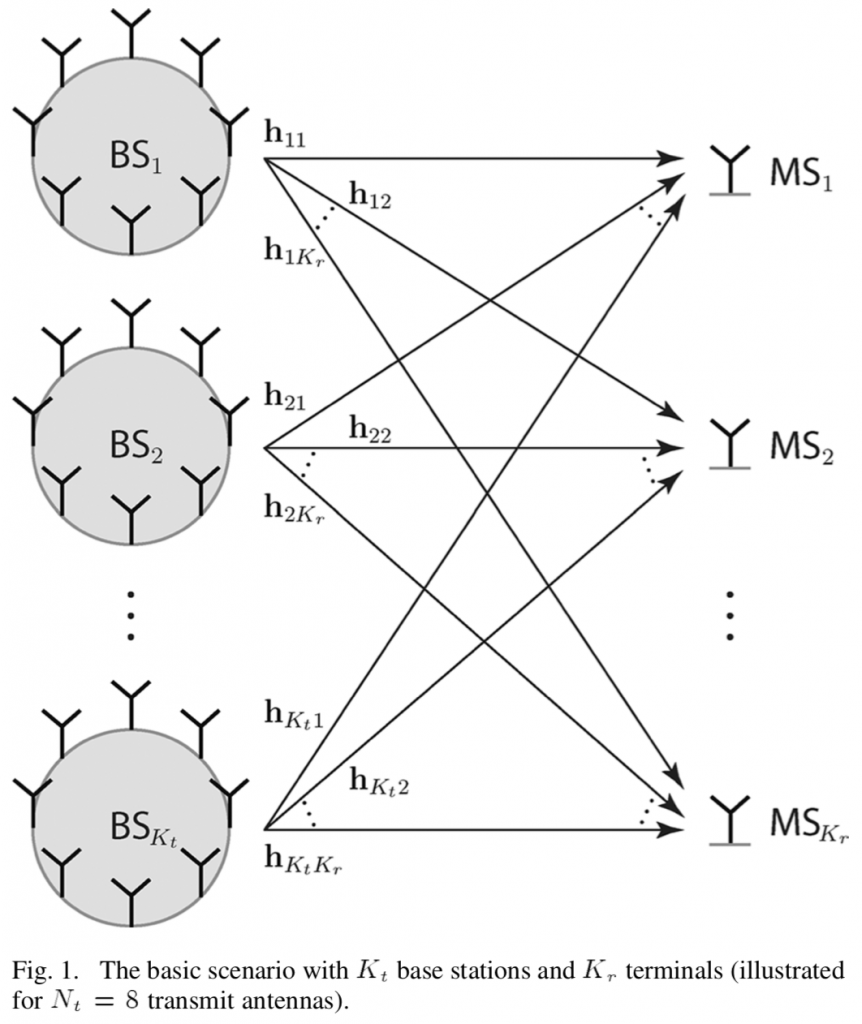
from an  -antenna base station can consist of multiple information signals that are transmitted using different precoding (e.g., different spatial directivity). When there are
-antenna base station can consist of multiple information signals that are transmitted using different precoding (e.g., different spatial directivity). When there are  unit-power data signals
unit-power data signals  intended for
intended for 
 are the
are the  determines the spatial directivity of the signal
determines the spatial directivity of the signal  , while the squared norm
, while the squared norm  determines the associated transmit power. Massive MIMO usually means that
determines the associated transmit power. Massive MIMO usually means that  .
. and we define the
and we define the  precoding matrix
precoding matrix![\begin{equation*} \mathbf{W} = [\mathbf{w}_1 \, \, \ldots \,\, \mathbf{w}_K],\end{equation*}](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-ae758aa3911d54d42af75805c2c641be_l3.png "Rendered by QuickLaTeX.com")
 equals the maximum transmit power:
equals the maximum transmit power:
![\mathbf{F} = [\mathbf{f}_1 \, \, \ldots \,\, \mathbf{f}_K]](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-6881dc5d4c10cf080eb2e99adce868d7_l3.png "Rendered by QuickLaTeX.com") and then adapt it to satisfy the power constraint in (3).
and then adapt it to satisfy the power constraint in (3). and scales all the entries with the same number, which is selected to satisfy (3). More precisely, we select
and scales all the entries with the same number, which is selected to satisfy (3). More precisely, we select
 to satisfy (3). More precisely, we select
to satisfy (3). More precisely, we select![\begin{equation*}\mathbf{W} = \sqrt{\frac{P}{K}} \left[ \frac{\mathbf{f}_1}{\| \mathbf{f}_1\|} \, \, \ldots \,\, \frac{\mathbf{f}_K}{\| \mathbf{f}_K\|} \right].\end{equation*}](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-1133ed1407eb95745fc1b99857aa1a3a_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*}\mathbf{W} = \left[ \sqrt{p_1} \frac{\mathbf{f}_1}{\| \mathbf{f}_1\|} \, \, \ldots \,\, \sqrt{p_K} \frac{\mathbf{f}_K}{\| \mathbf{f}_K\|} \right],\end{equation*}](https://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-5d334315910109cd0d1fe1d2ddbf8916_l3.png "Rendered by QuickLaTeX.com")
 are variables representing the power assigned to each of the users. These should be carefully selected to maximize some performance goals of the network, such as the sum rate, proportional fairness, or max-min fairness. In any case, the power allocation must be selected to satisfy the constraint
are variables representing the power assigned to each of the users. These should be carefully selected to maximize some performance goals of the network, such as the sum rate, proportional fairness, or max-min fairness. In any case, the power allocation must be selected to satisfy the constraint 