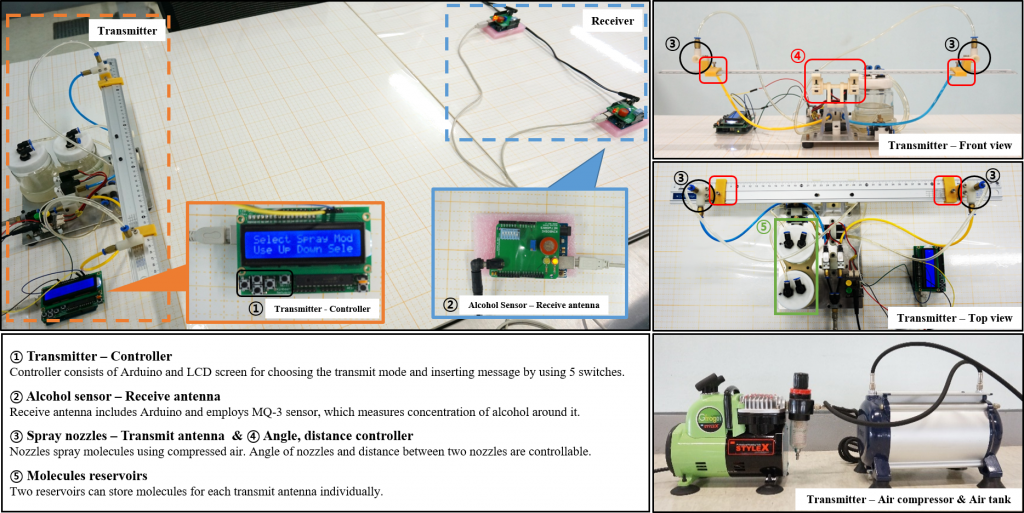
One more reason to attend the IEEE CTW 2019: Participate in the Molecular MIMO competition! There is a USD 500 award to the winning team.
The task is to design a molecular MIMO communication detection method using datasets that contain real measurements. Possible solutions may include classic approaches (e.g., thresholding-based detection) as well as deep learning-based approaches.
Ever since I finished the writing of the book Massive MIMO Networks: Spectral, Energy, and Hardware Efficiency, I have felt that I’m somewhat done with my research on conventional Massive MIMO. The spectral efficiency, energy efficiency, resource allocation, and pilot contamination phenomenon are well understood by now. This is not a bad thing—as researchers, we are supposed to solve the problems we are analyzing. But it means that this is a good time to look for new research directions. It should preferably be something where we can utilize our skills as Massive MIMO researchers to do something new and exciting!
With this in mind, I gathered a team consisting of myself, Luca Sanguinetti, Henk Wymeersch, Jakob Hoydis, and Thomas L. Marzetta. Each one of us has written about one promising new direction of research related to antenna arrays and MIMO, including the background of the topic, our long-term vision, and pertinent open problem. This resulted in the paper:
You can find the preprint on arXiv.org or by clicking on the name of the paper. I hope that you will find it as interesting to read as it was for us to write!
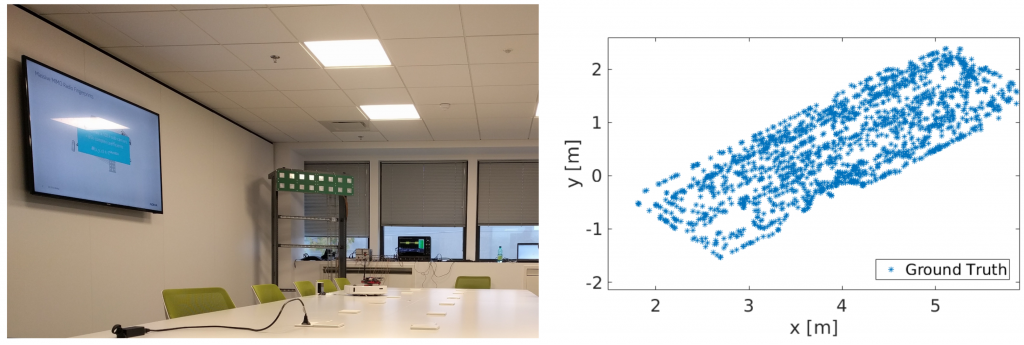
The object of the competition is to design and train an algorithm that can determine the position of a user, based on estimated channel frequency responses between the user and an antenna array. Possible solutions may build on classic algorithms (fingerprinting, interpolation) or machine-learning approaches. Channel vectors from a dataset created with a MIMO channel sounder will be used.
Competing teams should present a poster at the conference, describing their algorithms and experiments.
A $500 USD prize will be awarded to the winning team.
Come listen to Liesbet Van der Perre, Professor at KU Leuven (Belgium) on Monday February 18 at 2.00 pm EST.
She gives a webinar on state-of-the-art circuit implementations of Massive MIMO, and outlines future research challenges. The webinar is based on, among others, this paper.
In more detail the webinar will summarize the fundamental technical contributions to efficient digital signal processing for Massive MIMO. The opportunities and constraints on operating on low-complexity RF and analog hardware chains are clarified. It will explain how terminals can benefit from improved energy efficiency. The status of technology and real-life prototypes will be discussed. Open challenges and directions for future research are suggested.
This chip-scale atomic clock (CSAC) device, developed by Microsemi, brings atomic clock timing accuracy (see the specs available in the link) in a volume comparable to a matchbox, and 120 mW power consumption. This is way too much for a handheld gadget, but undoubtedly negligible for any fixed installation powered from the grid. An alternative to synchronization through GNSS that works anywhere, including indoor in GNSS-denied environments.
I haven’t seen a list price, and I don’t know how much exotic metals and what licensing costs that its manufacture requires, but let’s ponder the possibility that a CSAC could be manufactured for the mass-market for a few dollars each. What new applications would then become viable in wireless?
The answer is mostly (or entirely) speculation. One potential application that might become more practical is positioning using distributed arrays. Another is distributed multipair relaying. Here and here are some specific ideas that are communication-theoretically beautiful, and probably powerful, but that seem to be perceived as unrealistic because of synchronization requirements. Perhaps CoMP and distributed MIMO, a.k.a. “cell-free Massive MIMO”, applications could also benefit.
Other applications might be applications for example in IoT, where a device only sporadically transmits information and wants to stay synchronized (perhaps there is no downlink, hence no way of reliably obtaining synchronization information). If a timing offset (or frequency offset for that matter) is unknown but constant over a very long time, it may be treated as a deterministic unknown and estimated. The difficulty with unknown time and frequency offsets is not their existence per se, but the fact that they change quickly over time.
It’s often said (and true) that the “low” speed of light is the main limiting factor in wireless. (Because channel state information is the main limiting factor of wireless communications. If light were faster, then channel coherence would be longer, so acquiring channel state information would be easier.) But maybe the unavailability of a ubiquitous, reliable time reference is another, almost as important, limiting factor. Can CSAC technology change that? I don’t know, but perhaps we ought to take a closer look.
When I went to high school in Sweden, some of my friends stayed up very late at night (due to the time difference) to watch the Super Bowl; the annual championship in the American football league. This game is generally not a big thing in Sweden, but it is huge in America.
This Sunday, the Super Bowl takes place in Atlanta and one million people are expected to come to downtown Atlanta, to either watch the game at the stadium or root for their teams in other ways. Hence, massive flows of images and videos will be posted on social media from people located in a fairly limited area. To prepare for the game, the telecom operators have upgraded their cellular networks and taken the opportunity to market their 5G efforts.
Massive MIMO in the sub-6 GHz band with 64 antennas (and 128 radiating elements) is a key technology to handle the given situation, where huge capacity can be achieved by spatially multiplexing a large number of users in the downtown. Massive MIMO is a “small box with a massive impact” Cyril Mazloum, Network Manager for Sprint in Atlanta, told Hypepotamus. This refers to the fact that the Massive MIMO equipment is, despite the naming, physically smaller than the legacy equipment it replaces. In the following video, Heather Campbell of the Sprint Network Team explains how a ten times higher capacity is achieved in the 2.5 GHz band by their Massive MIMO deployment, which I have also reported about before.
All the major cellular operators have upgraded their networks in preparation for the big game. AT&T has reportedly spent $43 million to deploy 1,500 new antennas. Verizon has installed 30 new macro sites, 300 new small cells, and upgraded the capacity of 150 existing sites. T-Mobile has reportedly boosted its network capacity by eight times. Massive MIMO and 5G are clearly one of the key technologies in all these cases.
When an antenna array is used to focus a transmitted signal on a receiver, we call this beamforming (or precoding) and we usually illustrate it as shown to the right. This cartoonish illustration is only applicable when the antennas are gathered in a compact array and there is a line-of-sight channel to the receiver.
If we want to deploy very many antennas, as in Massive MIMO, it might be preferable to distribute the antennas over a larger area. One such deployment concept is called Cell-free Massive MIMO. The basic idea is to have many distributed antennas that are transmitting phase-coherently to the receiving user. In other words, the antennas’ signal components add constructively at the location of the user, just as when using a compact array for beamforming. It is therefore convenient to call it beamforming in both cases—algorithmically it is the same thing!
The question is: How can we illustrate the beamforming effect when using a distributed array?
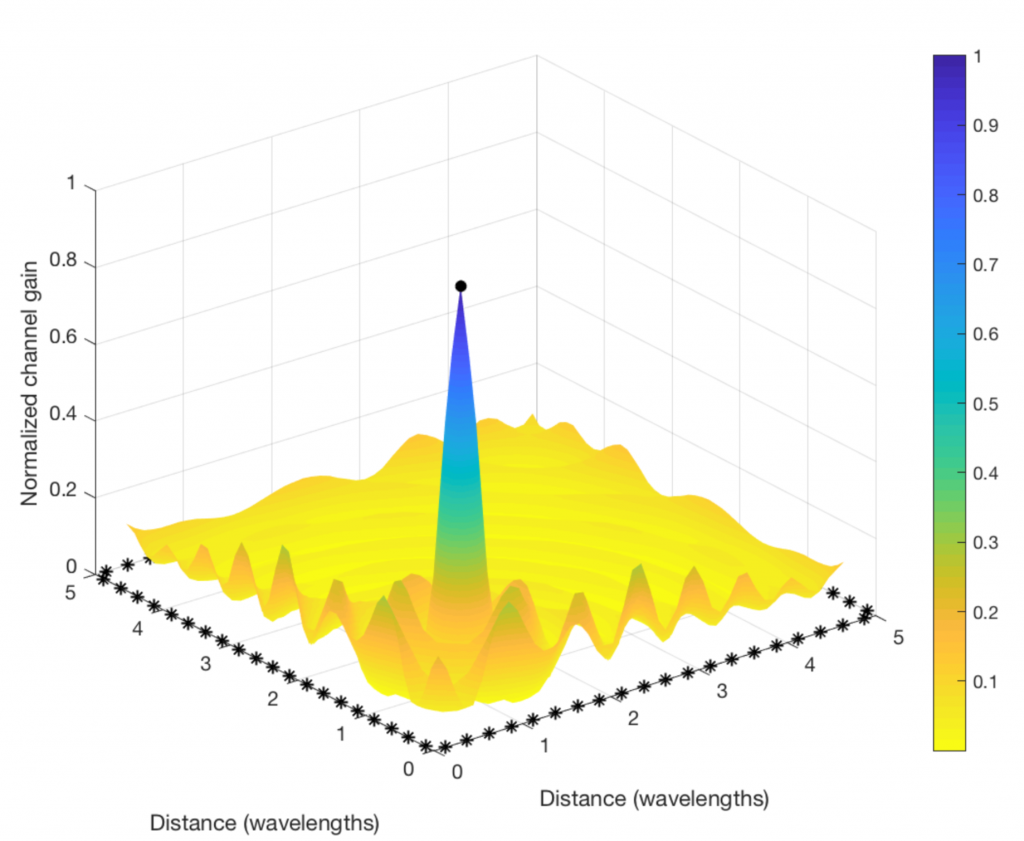
The figure below shows how to do it. I consider a toy example with 80 star-marked antennas deployed along the sides of a square and these antennas are transmitting sinusoids with equal power, but different phases. The phases are selected to make the 80 sine-components phase-aligned at one particular point in space (where the receiving user is supposed to be):
Clearly, the “beamforming” from a distributed array does not give rise to a concentrated signal beam, but the signal amplification is confined to a small spatial region (where the color is blue and the values on the vertical axis are close to one). This is where the signal components from all the antennas are coherently combined. There are minor fluctuations in channel gain at other places, but the general trend is that the components are non-coherently combined everywhere except at the receiving user. (Roughly the same will happen in a rich multipath channel, even if a compact array is used for transmission.)
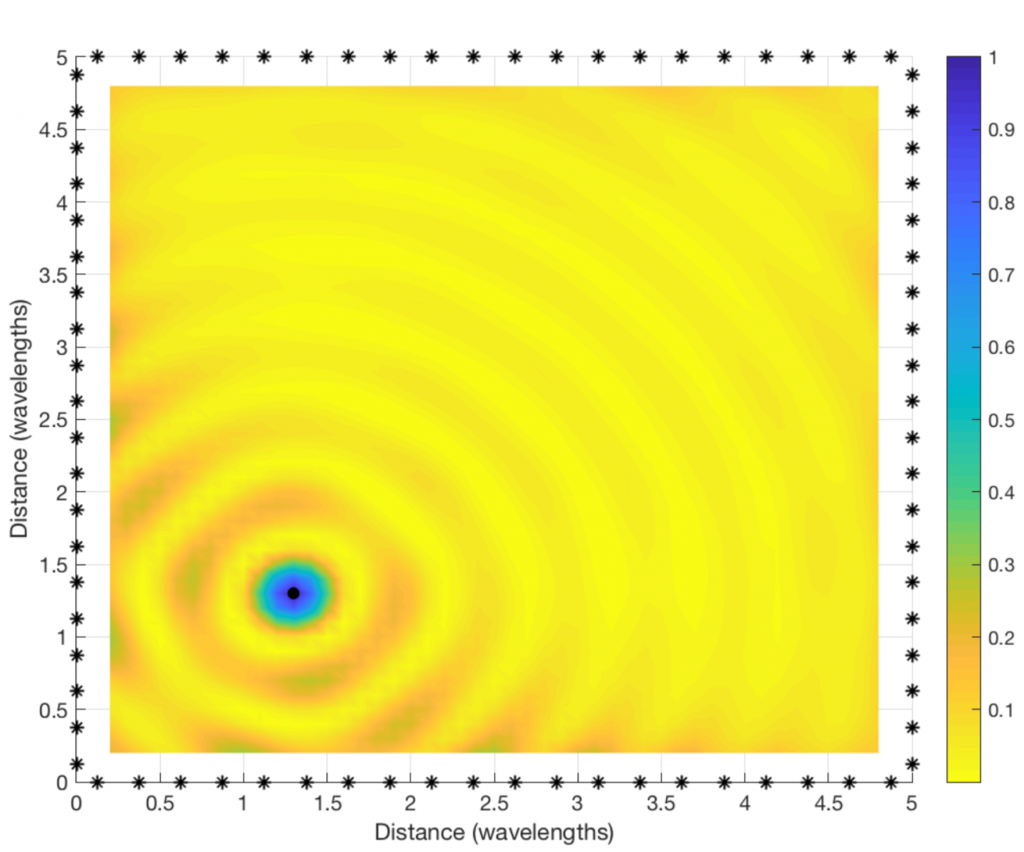
By looking at a two-dimensional version of the figure (see below), we can see that the coherent combination occurs in a circular region that is roughly half a wavelength in diameter. At the carrier frequencies used for cellular networks, this region will only be a few centimeters or millimeters wide. It is almost magical how this distributed array can amplify the signal at such a tiny spatial region! This spatial region is probably what the company Artemis is calling a personal cell (pCell) when marketing their distributed MIMO solution.
If you are into the details, you might wonder why I simulated a square region that is only a few wavelengths wide, and why the antenna spacing is only a quarter of a wavelength. This assumption was only made for illustrative purposes. If the physical antenna locations are fixed but we would reduce the wavelength, the size of the circular region will reduce and the ripples will be more frequent. Hence, we would need to compute the channel gain at many more spatial sample points to produce a smooth plot.
Reproduce the results: The code that was used to produce the plots can be downloaded from my GitHub.