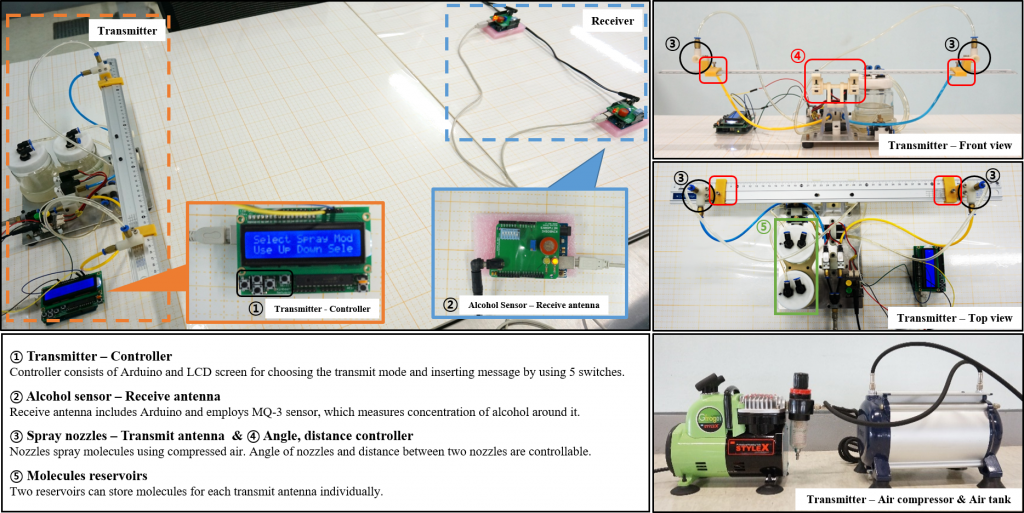
One more reason to attend the IEEE CTW 2019: Participate in the Molecular MIMO competition! There is a USD 500 award to the winning team.
The task is to design a molecular MIMO communication detection method using datasets that contain real measurements. Possible solutions may include classic approaches (e.g., thresholding-based detection) as well as deep learning-based approaches.
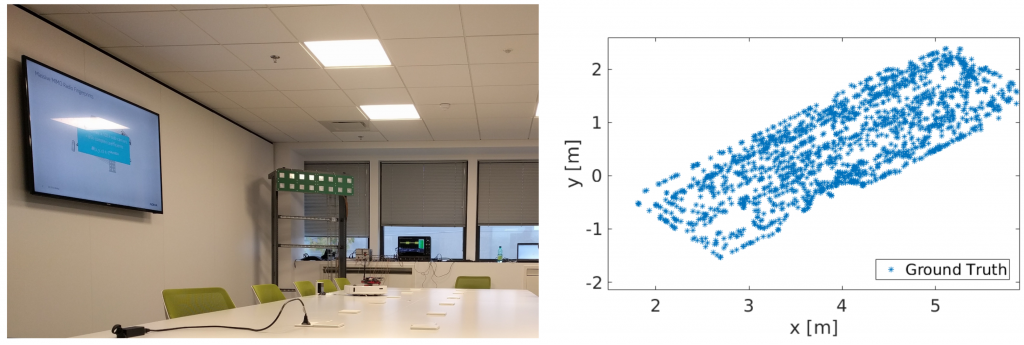
The object of the competition is to design and train an algorithm that can determine the position of a user, based on estimated channel frequency responses between the user and an antenna array. Possible solutions may build on classic algorithms (fingerprinting, interpolation) or machine-learning approaches. Channel vectors from a dataset created with a MIMO channel sounder will be used.
Competing teams should present a poster at the conference, describing their algorithms and experiments.
A $500 USD prize will be awarded to the winning team.
When I went to high school in Sweden, some of my friends stayed up very late at night (due to the time difference) to watch the Super Bowl; the annual championship in the American football league. This game is generally not a big thing in Sweden, but it is huge in America.
This Sunday, the Super Bowl takes place in Atlanta and one million people are expected to come to downtown Atlanta, to either watch the game at the stadium or root for their teams in other ways. Hence, massive flows of images and videos will be posted on social media from people located in a fairly limited area. To prepare for the game, the telecom operators have upgraded their cellular networks and taken the opportunity to market their 5G efforts.
Massive MIMO in the sub-6 GHz band with 64 antennas (and 128 radiating elements) is a key technology to handle the given situation, where huge capacity can be achieved by spatially multiplexing a large number of users in the downtown. Massive MIMO is a “small box with a massive impact” Cyril Mazloum, Network Manager for Sprint in Atlanta, told Hypepotamus. This refers to the fact that the Massive MIMO equipment is, despite the naming, physically smaller than the legacy equipment it replaces. In the following video, Heather Campbell of the Sprint Network Team explains how a ten times higher capacity is achieved in the 2.5 GHz band by their Massive MIMO deployment, which I have also reported about before.
All the major cellular operators have upgraded their networks in preparation for the big game. AT&T has reportedly spent $43 million to deploy 1,500 new antennas. Verizon has installed 30 new macro sites, 300 new small cells, and upgraded the capacity of 150 existing sites. T-Mobile has reportedly boosted its network capacity by eight times. Massive MIMO and 5G are clearly one of the key technologies in all these cases.
Although there are nowadays many Massive MIMO testbeds around the world, there are very few open datasets with channel measurement results. This will likely change over the next few years, spurred by the need for having common datasets when applying and evaluating machine learning methods in wireless communications.
The Networked Systems group at KU Leuven has recently made the results from one of their measurement campaigns openly available. It includes 36 user positions and two base station configurations: one 64-antenna co-located array and one distributed deployment with two 32-antenna arrays.
The following video showcases the measurement setup:
If you are following the 5G news, you might have noticed the many claims from various operators and telecom manufactures of being first with 5G. How can more than one company be first?
One telling example from this week is that on Thursday, Sprint/Nokia/Qualcomm reported about the “First 5G Data Call Using 2.5 GHz” and on Friday, Ericsson/Qualcomm reported about a “5G data call on 2.6 GHz band (…) adding a new frequency band to those successfully tested for commercial deployment.” The difference in carrier frequency is so small that I suppose the same hardware could have been used in both bands; for example, the LTE Massive MIMO product that I wrote about last August is designed for the frequency range 2496-2690 MHz. Yet, there is no contradiction between the two press releases; there are many different frequency bands and 5G features that one can be the first to demonstrate the use of, so we will likely see many more reports like these ones.
SOURCE Sprint
The multitude of press releases of this kind is an indicator of: 1) The many tests of soon-to-be-released hardware that are ongoing; 2) The importance for the companies to push out a steady stream of 5G related news.
When it comes to Massive MIMO, Sprint has previously showcased their use of fully digital 64-antenna panels at sub-6 GHz frequencies. In the new press release, they mention that hundreds of such panels were deployed in their network in 2018. Dr. Wen Tong, Head of Wireless Research at Huawei, made a similar claim about China in his keynote at GLOBECOM 2018. These are of course very small numbers compared to the millions of LTE base stations that exist in the world, but it indicates how important Massive MIMO will be in 5G. In fact, there are good reasons to believe that some kind of Massive MIMO technology will be used in almost every 5G base station.
2018 was the year when the deployment of Massive MIMO capable base stations began in many countries, such as Russia and USA. Nevertheless, I still see people claiming that Massive MIMO is “too expensive to implement“. In fact, this particular quote is from a review of one of my papers that I received in November 2018. It might have been an accurate (but pessimistic) claim a few years ago, but nowadays it is plainly wrong.
This photo is from the Bristol Temple Meads railway station. The Massive MIMO panel is at the bottom. (Photo: Vodafone UK Media Centre.)
I recently came across a website about telecommunication infrastructure by Peter Clarke. He has gathered photos of Massive MIMO antenna panels that have been deployed by Vodafone and by O2 in the United Kingdom. These deployments are using hardware from Huawei and Nokia, respectively. Their panels have similar form factors and are rather easy to recognize in the pictures since they are almost square-shaped, as compared to conventional rectangular antenna panels. You can see the difference in the image to the right. The technology used in these panels are probably similar to the Ericsson panel that I have previously written about. I hope that as many wireless communication researchers as possible will see these images and understand that Massive MIMO is not too expensive to implement but has in fact already been deployed in commercial networks.
I was asked to review my ownpapers three times during 2018. Or more precisely, I was asked to review papers by other people that contain the same content as some of my most well-cited papers. The review requests didn’t come from IEEE journals but less reputed journals. However, the papers were still written in such a way that they would likely pass through the automatic plagiarism detection systems that IEEE, EDAS, and others are using. How is that possible? Here is an example of how it could look like.
Original:
Plagiarized version:
As you can see, the authors are using the same equations and images, but the sentences are slightly paraphrased and the inline math is messed up. The meanings of the sentences are the same, but the different wording might be enough to pass through a plagiarism detection system that compares the words in different documents without being able of understanding the context. (I have better examples of this than the one shown above, but I didn’t want to reveal myself as a reviewer of those papers.)
This approach to plagiarism is known as rogeting and basically means that you replace words in the original text with synonyms from a thesaurus with the purpose of fooling plagiarism detection systems. There are already online tools that can do this, often resulting unnatural sentence structures, but the advances in deep learning and natural language processing will probably help to refine these tools in the near future.
Is this an increasing problem?
This is hard to tell, but there are definitely indications in that direction. The reason might be that digital technology has made it easier to plagiarize. If you want to plagiarize a scientific paper, you don’t need to retype every word by hand. You can simply download the LaTeX code of the paper from ArXiV.org (everything that an author uploads can be downloaded by others) and simply change the author names and then hide your misconduct by rogeting.
On the other hand, plagiarism detection systems are also becoming more sophisticated over time. My point is that we should never trust these systems as being reliable because people will always find ways to fool them. The three plagiarized papers that I detected in 2018 were all submitted to less reputed journals, but they apparently had a functioning peer-review system where researchers like me could spot the similarities despite the rogeting. Unfortunately, there are plenty of predatory journals and conferences that might not have any peer-review whatsoever and will publish anything if you just pay them to do so.
Does anyone benefit from plagiarism?
I am certainly annoyed by the fact that some people have the dishonesty to steal other people’s research and pretend that it is their research. At the same time, I’m wondering if anyone really benefits from doing that? The predatory journals make money from it, but what is in it for the authors? Whenever I review the CV of someone that applies for a position in my group, I have a close look at their list of publications. If it only contains papers published in unknown journals and conferences, I treat it as if the person has no real publications. I might even regard it as more negative to have such publications in the CV than to have no publications at all! I suppose that many other professors do the same thing, and I truly hope that recruiters at companies also have the skills of evaluating publication lists. Having published in a predatory journal must be viewed as a big red flag!