We have now released the 35th episode of the podcast Wireless Future. It has the following abstract:
The main directions for 6G research have been established and include pushing the communication to higher frequency bands, creating smart radio environments, and removing the conventional cell structure. There are many engineering issues to address on the way to realizing these visions. In this episode, Emil Björnson and Erik G. Larsson discuss the article “The Road to 6G: Ten Physical Layer Challenges for Communications Engineers” from 2021. What specific research challenges did the authors identify, and what remains to be done? The conversation covers system modeling complexity, hardware implementation issues, and signal processing scalability. The article can be found here: https://arxiv.org/pdf/2004.07130 The following papers were also mentioned: https://arxiv.org/pdf/2111.15568 and https://arxiv.org/pdf/2104.15027
You can watch the video podcast on YouTube:
https://youtu.be/t4W4OEPtsuQ
You can listen to the audio-only podcast at the following places:
When I first heard Tom Marzetta describe Massive MIMO with an infinite number of antennas, I felt uncomfortable since it challenged my way of thinking about MIMO. His results and conclusions seemed too good to be true and were obtained using a surprisingly simple channel model. I was a Ph.D. student then and couldn’t pinpoint specific errors, but I sensed something was wrong with the asymptotic analysis.
I’ve later grown to understand that Massive MIMO has all the fantastic features that Marzetta envisioned in his seminal paper. Even the conclusions from his asymptotic analysis are correct, even if the choice of model overemphasizes the impact of pilot contamination. The only issue is that one cannot reach all the way to the asymptotic limit, where the number of antennas is infinite.
Assuming that the universe is infinite, we could indeed build an infinitely large antenna array. The issue is that the uncorrelated and correlated fading models that were used for asymptotic Massive MIMO analysis during the last decade will, as the number of antennas increases, eventually deliver more signal power to the receiver than was transmitted. This breaches a fundamental physical principle: the law of conservation of energy. Hence, the conventional channel models cannot predict the actual performance limits.
In 2019, Luca Sanguinetti and I finally figured out how to study the actual asymptotic performance limits. As the number of antennas and array size grow, the receiver will eventually be in the radiative near-field of the transmitter. This basically means that the outermost antennas contribute less to the channel gain than the innermost antennas, and this effect becomes dominant as the number of antennas goes to infinity. We published the analytical results in the article “Power Scaling Laws and Near-Field Behaviors of Massive MIMO and Intelligent Reflecting Surfaces“ in the IEEE Open Journal of the Communications Society. In particular, we highlighted the implications for both MIMO receivers, MIMO relays, and intelligent reflecting surfaces. I have explained our main insights in a previous blog post, so I will not repeat it here.
I am proud to announce that this article has received the 2023 IEEE Communications Society Outstanding Paper Award. We wrote this article to quench our curiosity without knowing that the analysis of near-field propagation would later become one of the leading 6G research directions. From our perspective, we just found an answer to a fundamental issue that had been bugging us for years and published it in case others would be interested. Another journal first rejected the paper; thus, this is also a story of how one can reach success with hard work, even when other researchers are initially skeptical of your results and their practical utility.
The following 5-minute video summarizes the paper neatly:
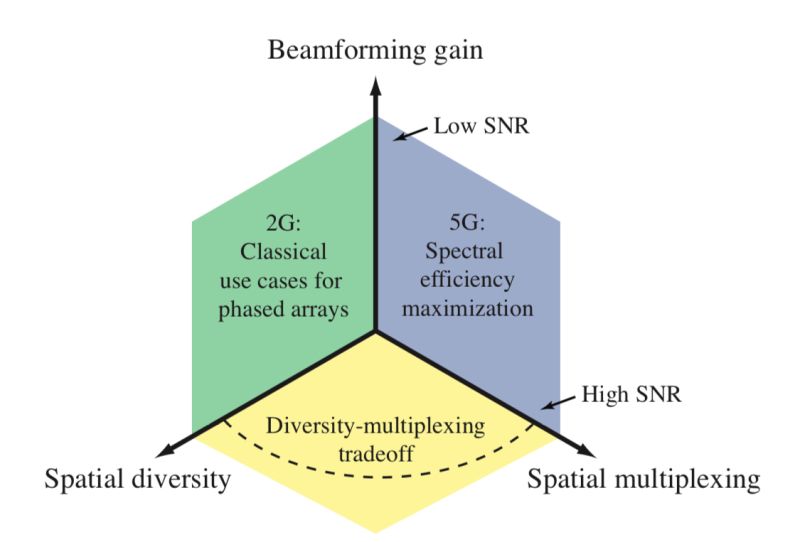
Multiantenna communications have a long and winding history, starting with how Guglielmo Marconi used an array of phase-aligned antennas to communicate over the Atlantic and Karl Ferdinand Braun used a triangular array to transmit phase-shifted signal copies to beamform in a controlled direction. The use of antenna arrays for spatial diversity and multiplexing has since appeared. The cellular network pioneer Martin Cooper tried to launch multi-user MIMO in the 1990s but concluded in 1996 that “computers weren’t powerful enough to operate it”.
During the last 25 years, multiantenna communications have changed from being a technology only used for beamforming and diversity, to becoming a mainstream enabler of high-capacity communication in 5G. It is used for both single-user and multi-user MIMO when connecting any modern mobile phone to the Internet, in both the 3 GHz and mmWave bands.
The IEEE Signal Processing Society is celebrating its 75 years anniversary and, therefore, the Signal Processing Magazine publishes a special issue focusing on the last 25 years of research developments. I have written a paper for this issue called “25 Years of Signal Processing Advances for Multiantenna Communications“. It is now available on arXiv, and it is co-authored by Yonina Eldar, Erik G. Larsson, Angel Lozano, and H. Vincent Poor. I hope you will like it!
We have now released the 34th episode of the podcast Wireless Future. It has the following abstract:
The speed of wired optical fiber technology is soon reaching 1 million megabits per second, also known as 1 terabit/s. Wireless technology is improving at the same pace but is 10 years behind in speed, thus we can expect to reach 1 terabit/s over wireless during the next decade. In this episode, Erik G. Larsson and Emil Björnson discuss these expected developments with a focus on the potential use cases and how to reach these immense speeds in different frequency bands – from 1 GHz to 200 GHz. Their own thoughts are mixed with insights gathered at a recent workshop at TU Berlin. Major research challenges remain, particularly related to algorithms, transceiver hardware, and decoding complexity.
You can watch the video podcast on YouTube:
You can listen to the audio-only podcast at the following places:
The core of the scientific method is that researchers perform experiments and analyses to make new discoveries, which are then disseminated to other researchers in the field. The discoveries that are accepted by the peers as scientifically valid and replicable become bricks of our common body of knowledge. As discoveries are primarily disseminated in scientific papers, these are scrutinized by other researchers for their correctness and must pass a quality threshold before publication. As an associate editor of a journal, you are managing this peer-review process for some of the submitted papers. The papers are assigned to editors based on their expertise and research interests. The editor is the one making the editorial decisions for the assigned papers and the decision to accept a paper for publication is never forgotten; the editor’s name is printed on the first page of the paper as a stamp of approval. The reputation of the journal and editor is lent to a published paper, thereby setting it aside from preprints and opinion pieces that anyone can share. To increase the likelihood of making a well-informed and fair editorial decision, you are asking peer reviewers to read the paper and provide their written opinions. The intention is that the reviewers consist of a diverse mix of established researchers that are well acquainted with the methodology used in the paper and/or previous work on the topic. To prevent herd mentality (e.g., people borrow assumptions from earlier papers without questioning their validity), it is also appropriate to ask a senior researcher working on an adjacent topic to provide an outsider perspective. Both TCOM and TGCN require at least three reviewers per paper, but exceptions can be made if reviewers drop out unexpectedly.
Finding suitable reviewers is either easy or hard, seldom in between. When handling a paper that is close to my daily research activities, I have a good sense of who are the skillful researchers within that topic and these people are likely to agree to my review requests since the paper matches their interests. However, when handling a paper that is further from my expertise, meaning that I critically need input from skillful reviewers to make the right decision, I had little clue of who to ask. My typical approach was to look for senior researchers that the authors have cited in the submitted paper, get automated suggestions from the editorial system, and make Google searches for papers with similar titles and keywords, to find published authors that are active in the field. I had to take the latter approach quite regularly when working for TGCN because the papers spanned a very wide range of topics related to energy-efficient communications. The result was often a mixed bag of reviews whose quality was hard to assess, which made me less confident with my editorial decisions.
The review time can vary substantially between papers, even if each reviewer is asked to deliver their review within 45 days. The extra delays either occur at the beginning or the end of the process. Only one third of the people that I invited to write reviews accepted my requests, so sometimes I had to invite new people in many rounds before three of them had accepted, which prolongs the process. It is also quite common that reviewers are not delivering their reviews on time. A few extra days are no big deal, but it is annoying when you must chase reviewers who are several weeks delayed. I urge people who get review requests to remember that it is perfectly fine to decline; you are wasting everyone’s time if you accept the request but cannot deliver on time.
When all the reviews had been received, I went through the paper and reviews to make up my mind on what decision to take: either reject the paper or ask the authors to revise it to address the key issues that have been identified. In principle, the paper can also be accepted immediately but that never happens in practice—no paper is perfect from the beginning. A major revision is basically the most positive decision you can expect from your initial submission, and it means that the editor thinks your paper can be accepted, if you properly address the issues that are brought up. Even if there are “major” things to address, they should still be limited in scope so that you as an editor see a viable path for them to be dealt with within two months. For example, if a flaw in the underlying models has been discovered, which can only be addressed by deriving new formulas and algorithms using entirely different methods and then re-running all the simulations, then I would reject the paper since the revised version would be too different from the initial one. Ideally, the required revisions should only affect a limited number of subsections, figures, and statements so it is sufficient for the editor and reviewer to re-read those parts to judge whether the issues have been addressed or not. Note that there is a path to publication also for papers that are initially rejected from TCOM or TGCN: if you can address the issues that were raised, you are allowed to resubmit the paper and get the same editor and reviewers again.
It is the editor who makes the decision; the reviewers only provide advice. It is therefore important to motivate your decision transparently towards the authors, particularly, when the reviewers have conflicting opinions and when there are certain issues that you want the authors to address in detail, while you think other comments are optional or even irrelevant. An example of the latter is when a reviewer asks the authors to cite irrelevant papers. Even when a reviewer has misunderstood the methodology or results, there are good reasons to revise the paper to avoid further misinterpretations of the paper. A good paper must be written understandably, in addition to having technical depth and rigor.
Things that characterize a good paper
The review process is not only assessing the technical content and scientific rigor, but also the significance, novelty, and usefulness of the paper to the intended readers. The evaluation against these criteria is varying with time since the new paper is compared with previous research; a paper that was novel and useful five years ago might be redundant today. For instance, it is natural that the first papers in a new field of communications make use of simplified models to search for basic insights and lead the way for more comprehensive research that uses more realistic models. Some years later, the simplified initial models are outdated and, thus, a new paper that builds on them will be of little significance and usefulness.
A concrete example during my tenure as editor is related to hybrid analog-digital beamforming. This is a wireless technology to be used in 5G over wideband channels in millimeter bands. The initial research focused on narrowband channels to gain basic insights but once the beamforming optimization was well understood in that special case, the community moved on to the practically useful wideband case. Nowadays, new papers that treat the narrowband case are mostly redundant. During my last two years, I therefore rejected most such submissions due to limited significance and usefulness.
I think a good paper identifies a set of unanswered research questions and finds concrete answers to them, by making discoveries (e.g., deriving analytical formulas, developing an efficient algorithm, or making experiments). This might seem obvious but many paper submissions that I handled did not have that structure. The authors had often identified a research gap in the sense of “this is the first paper that studies X under conditions Y and Z” but sometimes failed to motivate why that gap must be filled and what the research community can learn from that. Filling research gaps is commendable if we gain a deeper understanding of the fundamentals or bring previous results closer to reality. However, it might also make the research further and further detached from relevance. For example, one can typically achieve novelty by making a previously unthinkable set of assumptions, such as combining a conventional cellular network with UAVs, energy harvesting, secrecy constraints, hardware impairments, intelligent reflecting surfaces, and Nakagami fading—all at once! But such research is insignificant and maybe even useless.
Is the system broken?
The peer-review system receives criticism for being slow, unfair, and unable to catch all errors in papers, and I think the complaints are partially accurate. Some reviewers are submitting shallow or misleading reviews due to incompetence, rivalry, or lack of time, and the editors are not able to identify all those cases. The papers that I handled in TGCN were often outside my expertise, so I didn’t have the competence to make a deep review myself. Hence, when making my decision, I had to trust the reviewers and judge how critical the identified issues were. I have personally experienced how some editors are not even making that effort but let the reviewers fully decide on the outcome, which can lead to illogical decisions. It is possible to appeal an editorial decision in such situations, either by revising and resubmitting a rejected paper or contacting the editor (and editor-in-chief) to challenge the decision. My editorial decisions were never challenged in the latter way, but I have handled many resubmissions, whereof some were eventually accepted. I have complained about a few decisions on my own papers, which once led to the editor changing his mind but usually resulted in an encouragement to revise and resubmit the paper.
Despite the weaknesses of the peer-review process, I don’t think that abolishing the system is not the way forward. Half of all submitted papers are rejected, which is sad for the people who spent time writing them but greatly improves the average quality of the published papers. People who want to publish without scrutiny and having to argue with reviewers already have that option: upload a preprint to arXiv.org or use a pay-to-publish journal. I believe that scientific debate leads to better science and the peer-review system is the primary arena for this. The editor and reviewers might not catch all errors and are not always right, but they are creating a healthy resistance where the authors are challenged and must sharpen their arguments to convince their peers of the validity and importance of their discoveries. This is the first step in the process of accepting discoveries as parts of our common body of knowledge.
If I could change something in the publication process, I would focus on what happens after a paper has been accepted. We will never manage to make the peer-review process fully reliable, thus, there will always be errors in published papers. The journals that I’m familiar with handle error correction in an outdated manner: one cannot correct anything in the published paper, but one can publish a new document that explains what was wrong in the original version. This made sense in a time when journals were printed physically, but not in the digital era. I think published papers should become “living” documents that can be refined with time. For example, IEEEXplore could contain a feature where the readers of published papers can submit potential typos and the authors can respond, and possibly make corrections directly in the paper. Future readers will thereby obtain the refined version instead of the original one. To facilitate deeper scrutiny of published works, I also think it should become mandatory to attach data and simulation code to published papers; perhaps by turning papers into something that resembles Jupyter notebooks to ensure reproducibility. I’m occasionally informed about genuine errors in my papers or simulation code, which I gladly correct but I can never revise the officially published versions.
Was it worth it?
Being an editor is one of the unpaid duties that is expected from researchers that want to be active in the international research community. You are a facilitator of scientific debate and judge of research quality. The reason that scientifically skilled researchers are recruited instead of non-scientific administrators is that they should make the final informed publication decisions, not the reviewers. Editors are often recruited when they have established themselves as assistant or associate professors (or similar in the industry), either by being handpicked or volunteering. The experience that these people have accumulated is essential to making insightful decisions.
I learned many things about scientific publishing during my years as an associate editor, such as different ways to write papers and reviews, who I can trust to write timely and insightful reviews, and how to effectively deal with criticism. It was also not overly time-consuming because the journal makes sure that each editor handles a limited number of papers per year. You can free this time by declining an equal number of regular review requests. It was a useful experience that I don’t regret, and I recommend others to take on the editorial role. Maintaining high scientific standards is a community effort!
We have now released the 33rd episode of the podcast Wireless Future. It has the following abstract:
Research is carried out to obtain new knowledge, find solutions to pertinent problems, and challenge the researchers’ abilities. Two key aspects of the scientific process are reproducibility and replicability, which sound similar but are distinctly different. In this episode, Erik G. Larsson and Emil Björnson discuss these principles and their impact on wireless communication research. The conversation covers the replication crisis, Monte Carlo simulations, best practices, pitfalls that new researchers should avoid, and what the community can become better at. The following article is mentioned: “Reproducible Research: Best Practices and Potential Misuse”.
You can watch the video podcast on YouTube:
You can listen to the audio-only podcast at the following places:
The Wireless Future podcast is back with a new season. We have released the 32nd episode, which has the following abstract:
Information theory is the research discipline that establishes the fundamental limits for information transfer, storage, and processing. Major advances in wireless communications have often been a combination of information-theoretic predictions and engineering efforts that turn them into mainstream technology. Erik G. Larsson and Emil Björnson invited the information-theorist Giuseppe Caire, Professor at TU Berlin, to discuss how the discipline is shaping current and future wireless networks. The conversation first covers the journey from classical multiuser information theory to Massive MIMO technology in 5G. The rest of the episode goes through potential future developments that can be assessed through information theory: distributed MIMO, orthogonal time-frequency-space (OTFS) modulation, coded caching, reconfigurable intelligent surfaces, terahertz bands, and the use of ever larger numbers of antennas. The following papers are mentioned: “OTFS vs. OFDM in the Presence of Sparsity: A Fair Comparison”, “Joint Spatial Division and Multiplexing”, and “Massive MIMO has Unlimited Capacity”.
You can watch the video podcast on YouTube:
You can listen to the audio-only podcast at the following places: