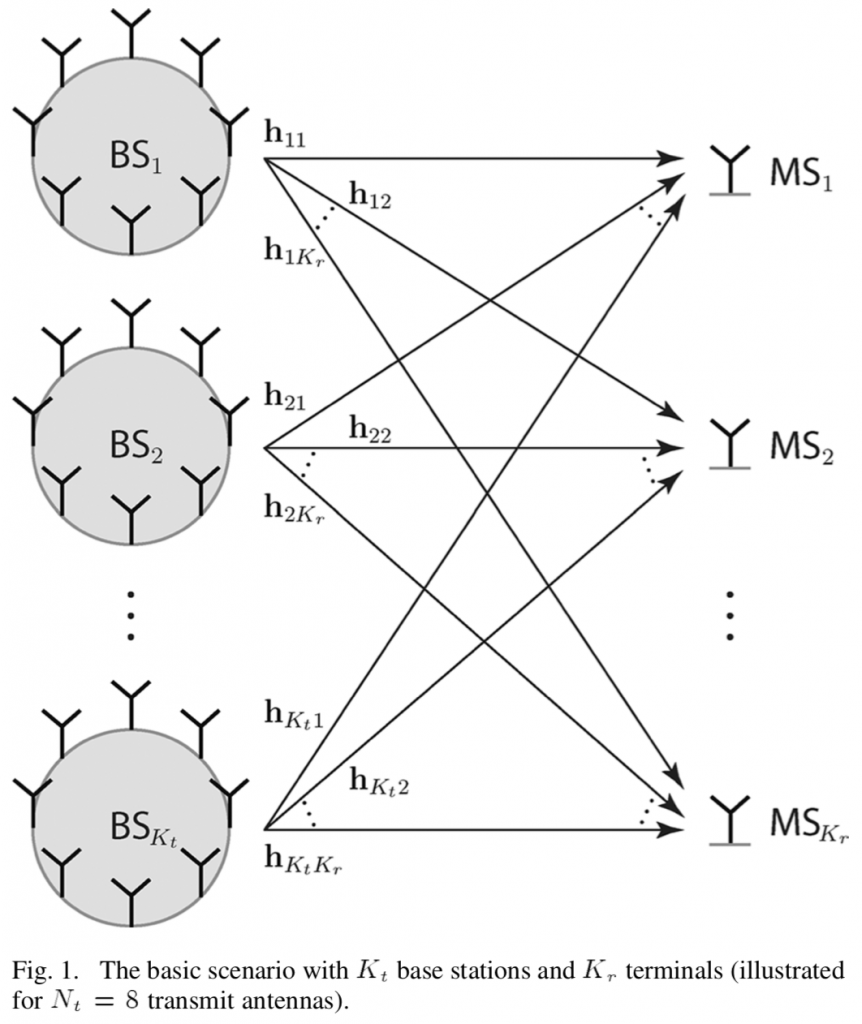
The new Cell-Free Massive MIMO concept has its roots in the classical Network MIMO concept, and has also been given many other names over the years (e.g., coordinated multipoint). When I started my research on the topic in 2009, the standard assumption was that a set of base stations were jointly transmitting to a set of users by sharing both the data signals and their respective channel state information (CSI). In my first journal paper, we showed that one can get away with only sharing the data signals between the base stations because each one only needs local CSI (between itself and the users) to beamform to the users. The price to pay is that the base stations cannot cancel each others’ interference, so each one should preferably have multiple antennas so it can control how much interference it causes. This was my first well-cited paper but, to be honest, I am still not sure how significant results are.
On the one hand, it is very convenient to only utilize local CSI at every base station, because it can be estimated from uplink pilots in a TDD system, which was a key motivation behind our 2010 paper. The time-critical precoding computation can then be initiated immediately after the pilots have been received, instead of waiting for the CSI to be shared between the base stations. This property was later utilized in the first Cell-Free Massive MIMO papers [Ngo, Nayebi] to alleviate the need for sharing CSI.
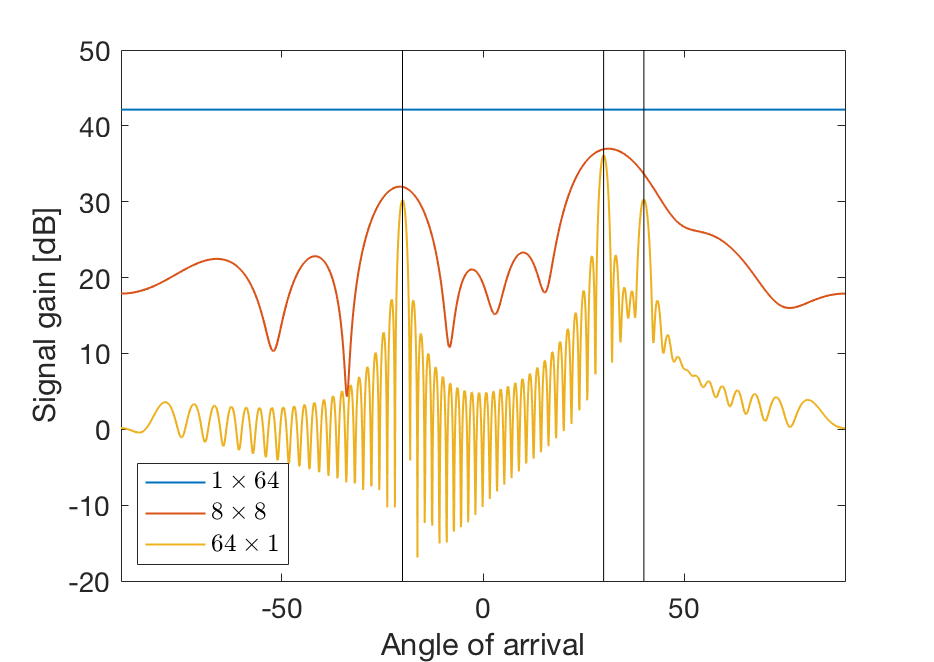
On the other hand, CSI is usually a small fraction of the signaling between a base station and the rest of the system in Network MIMO. The majority of the signaling consists of the data signals; for example, if a coherence block with 200 channel uses consists of 20 pilot symbols and 180 data symbols, then there is 180/20 = 9 times more data than CSI. Interestingly, our recent paper “Making Cell-Free Massive MIMO Competitive With MMSE Processing and Centralized Implementation” shows that if Cell-Free Massive MIMO is implemented by sending all CSI to an edge-cloud processor that takes care of all the signal processing, both the communication performance and the signaling load can be greatly improved as compared to the fully distributed approach (which was considered in my 2010 paper and then became the standard assumption in the Cell-Free Massive MIMO literature).
The bottom line is that it is hard to make a distributed network implementation competitive compared to a centralized one. Unless we can find a really clever implementation, there is a risk that we lose too much in communication performance and also raise the fronthaul capacity requirements.
 from an
from an  -antenna base station can consist of multiple information signals that are transmitted using different precoding (e.g., different spatial directivity). When there are
-antenna base station can consist of multiple information signals that are transmitted using different precoding (e.g., different spatial directivity). When there are  unit-power data signals
unit-power data signals  intended for
intended for 
 are the
are the  determines the spatial directivity of the signal
determines the spatial directivity of the signal  , while the squared norm
, while the squared norm  determines the associated transmit power. Massive MIMO usually means that
determines the associated transmit power. Massive MIMO usually means that  .
. and we define the
and we define the  precoding matrix
precoding matrix![\begin{equation*} \mathbf{W} = [\mathbf{w}_1 \, \, \ldots \,\, \mathbf{w}_K],\end{equation*}](http://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-ae758aa3911d54d42af75805c2c641be_l3.png "Rendered by QuickLaTeX.com")
 equals the maximum transmit power:
equals the maximum transmit power:
![\mathbf{F} = [\mathbf{f}_1 \, \, \ldots \,\, \mathbf{f}_K]](http://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-6881dc5d4c10cf080eb2e99adce868d7_l3.png "Rendered by QuickLaTeX.com") and then adapt it to satisfy the power constraint in (3).
and then adapt it to satisfy the power constraint in (3). and scales all the entries with the same number, which is selected to satisfy (3). More precisely, we select
and scales all the entries with the same number, which is selected to satisfy (3). More precisely, we select
 to satisfy (3). More precisely, we select
to satisfy (3). More precisely, we select![\begin{equation*}\mathbf{W} = \sqrt{\frac{P}{K}} \left[ \frac{\mathbf{f}_1}{\| \mathbf{f}_1\|} \, \, \ldots \,\, \frac{\mathbf{f}_K}{\| \mathbf{f}_K\|} \right].\end{equation*}](http://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-1133ed1407eb95745fc1b99857aa1a3a_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*}\mathbf{W} = \left[ \sqrt{p_1} \frac{\mathbf{f}_1}{\| \mathbf{f}_1\|} \, \, \ldots \,\, \sqrt{p_K} \frac{\mathbf{f}_K}{\| \mathbf{f}_K\|} \right],\end{equation*}](http://ma-mimo.ellintech.se/wp-content/ql-cache/quicklatex.com-5d334315910109cd0d1fe1d2ddbf8916_l3.png "Rendered by QuickLaTeX.com")
 are variables representing the power assigned to each of the users. These should be carefully selected to maximize some performance goals of the network, such as the sum rate, proportional fairness, or max-min fairness. In any case, the power allocation must be selected to satisfy the constraint
are variables representing the power assigned to each of the users. These should be carefully selected to maximize some performance goals of the network, such as the sum rate, proportional fairness, or max-min fairness. In any case, the power allocation must be selected to satisfy the constraint